Everyone’s deploying analytics agents. Almost nobody’s getting production-grade results.
BARC’s 2026 Trend Monitor puts a number on the disconnect: 50% of organizations have AI agents in production, but only 27% use them for BI and analytics. Agents are everywhere — but they’re not being trusted with the business questions that matter.
So what’s driving that gap? In our research with BARC, we found that agentic analytics requires solving three interconnected problems simultaneously — and most organizations are only addressing one or two.
Three problems, not one
Context engineering makes your organization’s institutional knowledge — business definitions, semantic models, decision patterns, tribal knowledge — usable by AI at scale. This is the layer that determines whether an agent returns a trustworthy answer or a plausible-sounding wrong one. Without it, accuracy plateaus regardless of how capable the underlying model is.
Agent engineering is the orchestration and personalization layer. How do agents interpret questions, plan their approach, select the right data sources, and tailor responses to the person asking? The CFO and the Sales VP asking the same question should get appropriately framed answers. That requires persona-aware routing, session management, and reasoning logic that goes well beyond simple retrieval.
Distributed data access is the ability to connect to and query data across the full enterprise landscape — warehouses, SaaS applications, operational databases, on-premise systems — without requiring centralization. Most enterprise data can’t be moved into a single platform. Agents need to query it where it lives, in real time.
What we’ve found is that these three capabilities are deeply interdependent. Context engineering without data access means the agent knows the right definitions but can’t reach the data. Data access without context means the agent reaches everything but interprets it wrong. And agent engineering without either? A well-orchestrated system that confidently delivers wrong answers from incomplete data.
A framework for assessing maturity
Based on this analysis, we developed a framework to help organizations assess where they stand on the agentic analytics maturity curve. It’s structured around two sets of questions.
How complex is the problem you’re solving?
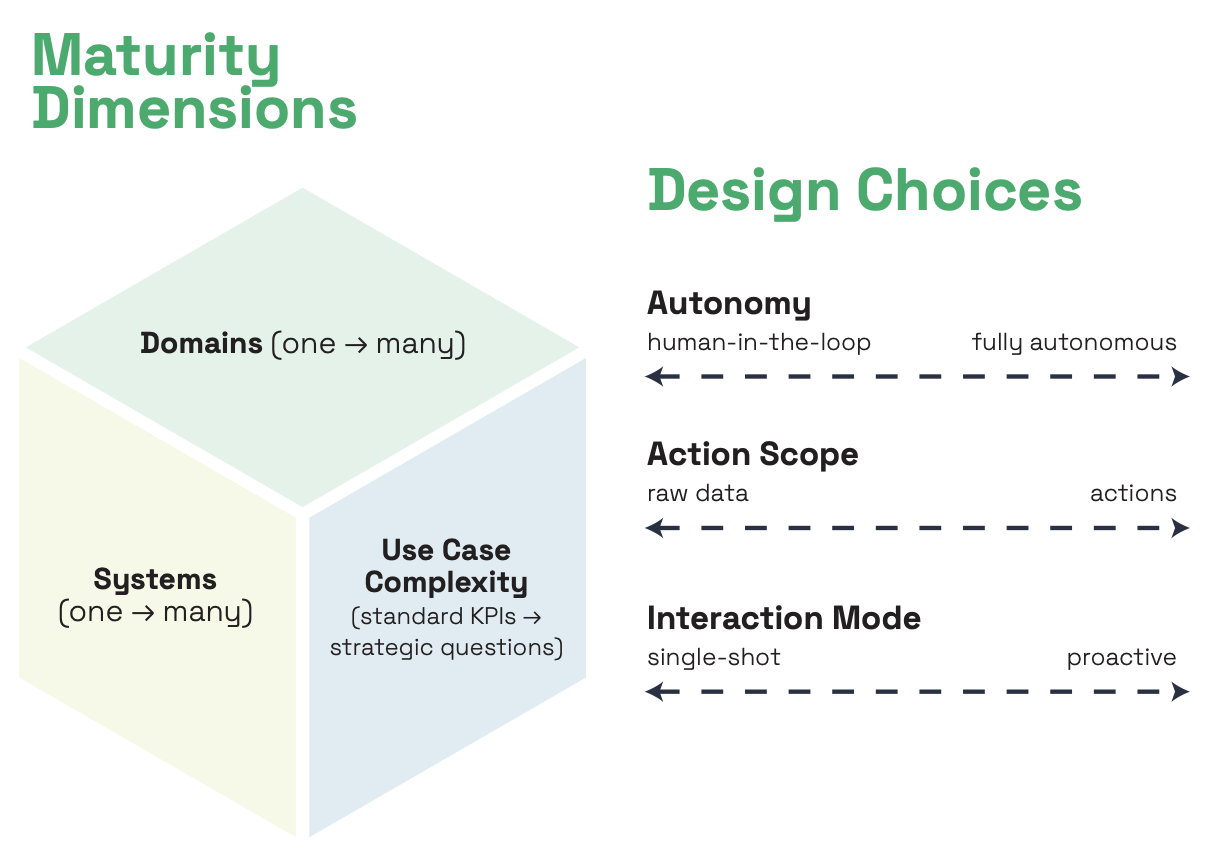
The first set addresses the system-level challenge — how hard is the agentic analytics problem for your specific organization? We’ve identified three dimensions that define this:
Data scope — how many systems do your agents need to access and reason across? A single warehouse is one thing. Adding CRM, SaaS applications, and on-premise sources introduces entirely different metadata formats, entity representations, and join logic. The broader the data landscape, the more sophisticated your access layer needs to be.
Use case complexity — how much context do your agents need to answer the questions being asked? Standard KPIs with well-defined metrics are manageable. Ad hoc exploration — where the agent has to figure out which data, definitions, and logic to apply — requires significantly deeper context. Cross-functional strategic questions require enterprise-wide context and a system that learns from usage.
Domain scope — how much personalization and use case variability do you need to build into the system? A single business domain is a contained problem. Spanning multiple domains means resolving conflicting definitions, managing cross-domain relationships, and building governance that scales. The more domains, the more context engineering compounds.
Each of these dimensions expands independently, and each expansion introduces new context engineering challenges. Most organizations we’ve analyzed sit early on all three — which explains why accuracy stalls and adoption doesn’t scale.
How should you design your agents?
The second set of questions addresses architectural choices — decisions that shape what kind of agentic system you’re building. We’ve identified three:
Autonomy — how much human oversight does the system require? From human-in-the-loop review of every answer to fully autonomous operation, this is a spectrum. And where you land should be driven by your context maturity, not your ambition.
Action scope — what does the system actually deliver? Raw data for human interpretation, interpreted insights, recommendations based on business context, or autonomous actions that trigger workflows? Each step up requires more context, more governance, and more trust.
Interaction mode — how do users engage with the system? Single-shot queries, multi-turn conversational exploration, or proactive monitoring that surfaces insights without being asked? Each mode demands fundamentally different context infrastructure.
These aren’t a progression from less to more. They’re architectural decisions that depend on your use cases, risk tolerance, and where your context infrastructure actually is today. A deliberately constrained design — human-in-the-loop, insights-level, single-shot — can be exactly right for a given stage of maturity.
Where do you stand?
Based on this framework, we’ve developed a self-assessment that helps organizations map where they are across all of these dimensions — and more importantly, identify the critical gaps that are holding them back.
What we’ve found in working with enterprises is that the most common failure pattern is expanding scope before context is ready. Giving business users access to an agent that can’t reliably handle ambiguity doesn’t demonstrate value — it erodes trust. And the design choices organizations make early on have lasting architectural implications that are expensive to reverse.
The full guide — including the self-assessment with scored sections across data landscape, context infrastructure, context gaps, current capabilities, and organizational readiness — is designed to be worked through with your data and analytics leadership team.