Boards expect AI to deliver immediate ROI. Data teams know the reality: 60% of AI initiatives fail to meet business SLAs — not because the models aren’t sophisticated enough, but because the data isn’t ready.
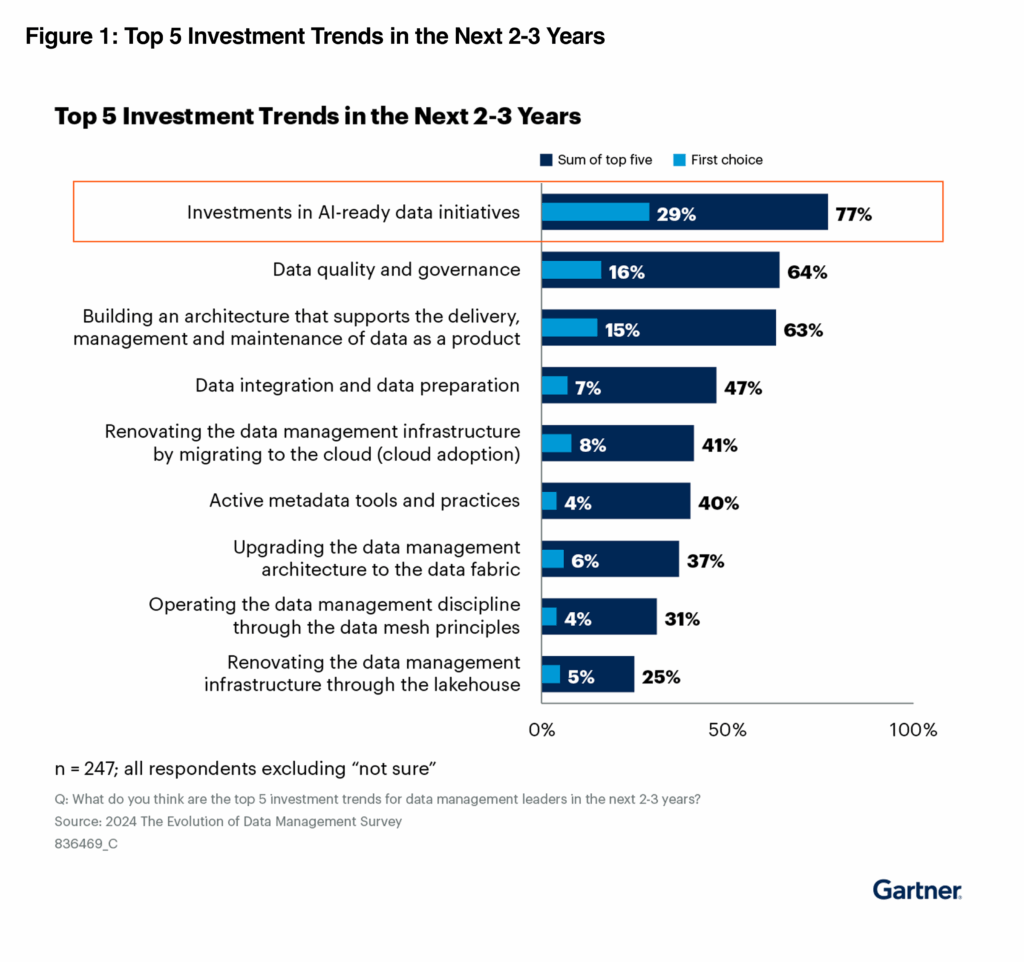
The gap is stunning. While 77% of organizations cite AI-ready data as a top investment priority, most struggle to define what “ready” actually means. Is it clean data? Complete data? Real-time data?
The answer is more demanding than traditional data management prepared us for.
The End User Has Changed
For decades, we built data systems for humans. Analysts queried databases. Business users read dashboards. Reports got printed and discussed in conference rooms.
In the future, AI agents will become the primary consumers of enterprise data. They don’t need visualizations or formatted reports. They need to understand not just what the data says, but what it means in your specific business domain — and they need it instantly, across all your systems.
This shift changes everything about how we think about data readiness.
What “AI-Ready” Actually Means
There’s no single definition of AI-ready data. Different frameworks emphasize different dimensions. Gartner focuses on three pillars: align contextually, qualify continuously, and govern contextually. Industry analysts Sanjeev Mohan highlights six key attributes: context, unification, accessibility, governance, accuracy, and iteration.
What they all agree on: AI-ready data is fundamentally different from the “clean data” we’ve optimized for analytics.
In essence, AI-ready data encompasses three critical factors:
It’s Contextual
Context goes beyond traditional metadata. A data dictionary might explain that customer_id is a customer identifier. AI needs to understand how customers relate to products, transactions, support tickets, and business outcomes — in your specific organization.
Without this context, AI makes confidently wrong decisions. It joins unrelated datasets. It applies metrics incorrectly. It draws conclusions from outdated information.
Context includes business definitions, data lineage, domain knowledge, and the unwritten rules that subject matter experts carry in their heads. The “correct” answer for revenue calculations differs between subscription businesses and e-commerce. Customer definitions vary between B2B and B2C. Product hierarchies follow company-specific logic.
Analytics users bring this expertise. AI models don’t — unless the context is embedded in the data itself.
It’s Unified and Accessible
AI doesn’t respect data silos. A customer service AI needs data from CRM systems, support tickets, product catalogs, and billing databases — all at once, in real time.
Traditional architectures fragment data by system, by department, by geography. Structured data lives in warehouses. Unstructured content sits in document repositories. Operational data stays in transactional systems.
AI can’t wait for data to be consolidated. Models operate at machine speed, requiring immediate access to fresh data across all relevant sources. This flips traditional architecture on its head.
For years, ETL was the gold standard: extract data, transform it, load it into a central warehouse. This introduced latency and created multiple copies that drift out of sync. By the time data arrives in the warehouse, business conditions may have already changed.
AI-ready data requires federation, not consolidation. Query data where it lives. Process it at the source. Eliminate the costly, time-consuming migration that delays AI value for months.
Modern data fabric architectures built on zero-copy principles deliver this accessibility without the infrastructure overhead of centralization. They create logical unification across physical boundaries — connecting structured and unstructured sources without forcing data movement.
It’s Governed
Traditional governance asks: “Can this user access this data?” AI-ready governance asks: “What will the AI do with this data, and is that outcome safe?”
This distinction matters because AI outputs are probabilistic, not deterministic. The same input data can produce different outputs depending on model state, training data, and context. Governing access isn’t enough — you need to govern how AI uses data and monitor what it produces.
AI-ready governance includes policy-as-code that enforces rules automatically at query time, continuous monitoring of model outputs for drift and anomalies, and audit trails showing exactly which data informed which decisions.
The goal: maintain comprehensive control without manual bottlenecks that kill innovation velocity. High-risk AI applications touching customer PII or making automated decisions operate under strict governance. Exploratory AI projects get broader access with automated guardrails. Production systems receive continuous monitoring.
Governance must also be iterative. AI models drift. Data distributions shift. Business definitions evolve. What qualified as AI-ready six months ago may no longer meet current needs. Continuous qualification — automated monitoring, iterative validation, and feedback loops — ensures data remains fit for purpose.
Why Traditional Data Management Falls Short
Here’s where AI-ready data diverges sharply from analytics-ready data:
- Analytics removes outliers as “noise.” AI training requires exactly those outliers to learn pattern recognition. A fraud detection model trained only on clean, normal transactions can’t identify fraud. When you remove the messy parts, you remove the signal AI needs.
- Analytics tolerates batch processing. AI applications — especially GenAI agents and real-time recommendation engines — can’t wait for overnight jobs. They need sub-second responses across distributed sources.
- Analytics assumes human domain expertise. Analysts know what “revenue” means in their business context. AI models need that knowledge explicitly embedded in metadata, lineage, and business definitions.
These differences explain why organizations with mature analytics capabilities still struggle with AI. The infrastructure, processes, and assumptions that worked for decades actively block AI readiness.
The Cost of Not Being Ready
The stakes are higher with AI than with traditional analytics.
When analytics data is wrong, dashboards break or display obviously flawed results. Someone notices the numbers don’t make sense and investigates.
When AI data isn’t ready, models confidently produce plausible but incorrect results. They hallucinate facts. They recommend actions based on incomplete context. They optimize for the wrong objectives.
By the time you notice the problem, the AI may have influenced thousands of decisions, eroded customer trust, or exposed the organization to compliance violations.
This is why 60% of AI initiatives fail. Not because of model limitations. Because the data wasn’t ready for how AI actually works.
Delivering AI-Ready Data Through Data Fabric
Meeting all three requirements — contextual, unified and accessible, governed — requires rethinking data architecture.
The pattern emerging among successful AI deployments:
- Start with federation, not consolidation. Deploy data fabric architectures that query data where it lives instead of spending months moving data into central repositories. This delivers immediate access while preserving existing investments.
- Automate context assembly. Manually documenting business definitions and domain knowledge doesn’t scale. Modern data fabrics aggregate metadata, lineage, and tribal knowledge automatically from existing catalogs, BI tools, and semantic layers.
- Govern at query time, not access time. Apply policies when data is actually used, not when it’s initially stored. This allows flexible, use-case-specific governance without rebuilding infrastructure for each new AI initiative.
Promethium’s Open Data Fabric delivers this approach: zero-copy access across your enterprise data, automated 360° context assembly, and query-level governance that enforces policies without bottlenecks. Organizations deploy in weeks and achieve 10× faster data preparation for AI initiatives.
Where to Start
You don’t need perfect AI-ready data to begin. You need enough readiness for your highest-priority use case — then you iterate.
Pick one high-value AI initiative. Don’t try to make all your data AI-ready at once.
Assess against the three factors. Where are the biggest gaps? Missing context? Data silos? Governance bottlenecks?
Address the critical blockers first. You might have great unification but terrible governance. Or excellent accessibility but no context. Fix what’s actually preventing your specific use case from succeeding.
Build data fabric infrastructure that scales. Point solutions might solve immediate problems, but AI initiatives multiply quickly. Invest in architecture that supports dozens or hundreds of AI projects without exponentially increasing complexity.
Want to dive deeper into AI-ready data best practices? Download your complimentary copy of Gartner’s comprehensive research report: A Journey Guide to Deliver AI Success Through AI-Ready Data. The report provides detailed frameworks for assessing data readiness, evolving data management practices, and implementing governance at scale.
Gartner, A Journey Guide to Deliver AI Success Through AI-Ready Data, By Ehtisham Zaidi, Roxane Edjlali, 11 July 2025.
GARTNER is a registered trademark and service mark of Gartner, Inc. and/or its affiliates in the U.S. and internationally and is used herein with permission. All rights reserved.
This graphic was published by Gartner, Inc. as part of a larger research document and should be evaluated in the context of the entire document. The Gartner document is available upon requests from Promethium.