Modern enterprises have no shortage of data — and even more questions about said data. But too often, every new request follows the exact same path: someone in the business asks for data, the data team scrambles to source and prepare it, and after a series of back-and-forth steps, the answer finally shows up in… a dashboard.
But here’s the thing: not every question needs a dashboard. In fact, many don’t. And when we treat every request like it does, we end up wasting time, building the wrong things, and frustrating both sides.
The Many Faces of a Data Request
When someone in the business asks for data, what they actually need can vary widely. Here are just a few types of requests:

- A dashboard for ongoing reporting and tracking
- A one-time number for a presentation or decision (e.g., “What was revenue last week in the UK?”)
- A clean dataset for building a machine learning model
- A slice of data to explore manually in Excel
- A data feed or API to integrate with another application
- A comparison or trend to support a business case
- A dataset to experiment with for a proof of concept or exploratory analysis
- A KPI that someone wants monitored continuously but doesn’t yet know if it’s worth operationalizing
- A diagnostic view to understand why something changed
- A test query to validate a hypothesis before deeper work begins
Each of these use cases is valid. But they all demand different types of responses — and different levels of investment. Yet in most organizations, there’s only one real path to answering any of them.
One Process to Rule Them All (Even When It Shouldn’t)
Today, even the smallest data request often kicks off a heavyweight process:
- Search for the right data across systems
- Figure out how to access it
- Build or modify a data pipeline
- Move the data via ETL
- Model and transform the data to fit internal schemas
- Build a dataset
- Query the data
- Create a dashboard or report
- Share it with the business
- Wait for feedback
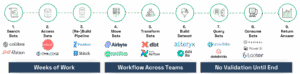
That’s a lot of effort before the business even sees the first draft of the answer. And what happens then?
The usual patterns include:
- “That’s not actually what I meant.” — Back to square one.
- “Great. Now I have another question.” — The cycle starts again.
- “Actually, I don’t need this anymore.” — Wasted work.
- “Thanks!” — And it’s never opened or used again.
Some companies estimate that over 60% of dashboards get looked at once or twice — then forgotten. They’re built with the best of intentions, but they’re not the right response for the request. The process is too rigid, too slow, and too resource-heavy for the pace and nature of today’s questions, especially in a world where AI is further shortening decision cycles.
The Cost of One-Size-Fits-All
This default approach creates real problems:
- It slows down decision-making. Teams wait days or weeks for answers to questions that could (or should) be resolved in minutes.
- It burns out data teams. Analysts spend more time building assets no one uses than solving high-value problems.
- It blocks self-service. Business users get stuck waiting, unable to explore or iterate independently.
- It over-engineers the trivial. Not every question deserves a production-grade pipeline.
The result? A data delivery model that doesn’t match how businesses actually work anymore.
Time for a Smarter Approach
What if instead of defaulting to dashboards and pipelines, we started by asking:
What kind of answer does this question really need?
- Is this a quick gut check or something to track over time?
- Does this need to be governed and reused, or just a throwaway?
- Will this inform a model, feed another system, or just support a one-time decision?
Starting with the question — not the pipeline — unlocks a more agile, fit-for-purpose model for delivering value from data.
In our next post, we’ll explore what that model can look like — and how the Data Answer concept is changing the game. Stay tuned!