Context Engineering vs RAG vs Fine-Tuning: Choosing the Right AI Data Strategy
Enterprise AI has reached an inflection point. Despite significant investments in large language models and data infrastructure, most organizations struggle to move beyond pilots. Recent evaluation frameworks reveal that only 16.3% of LLM-generated answers against heterogeneous enterprise systems are accurate enough for business decisions. The problem isn’t the AI itself—it’s the architecture underneath.
Three distinct approaches have emerged for making enterprise data usable for AI: retrieval-augmented generation (RAG), fine-tuning, and context engineering. While RAG connects LLMs to external knowledge and fine-tuning optimizes model parameters, context engineering represents a broader architectural discipline that treats information flow as a system-level design problem. Production-grade enterprise systems increasingly employ context engineering as the foundational layer that makes RAG and fine-tuning actually work.

What is a context graph and why are they the next evolution of context engineering?
Get your comprehensive guide now.
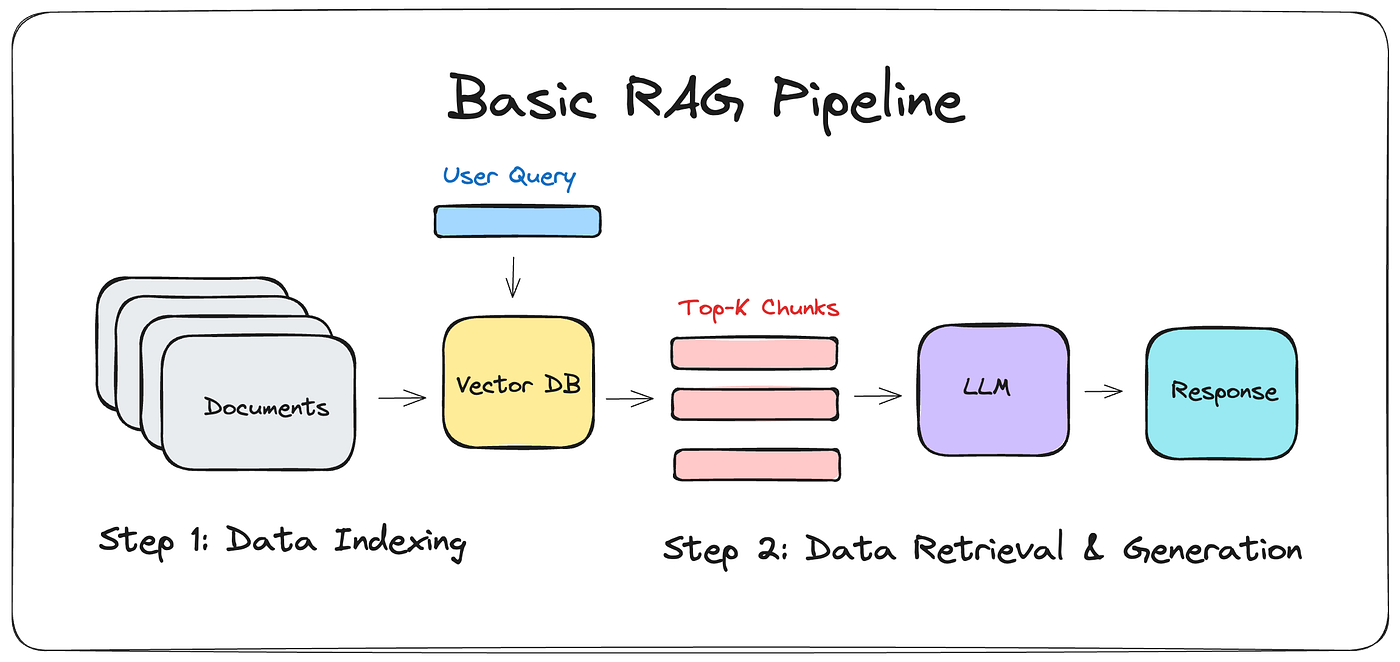
Understanding RAG: Capabilities and Enterprise Limitations
RAG emerged as a practical solution to a fundamental problem: LLMs encode only static knowledge from training data. RAG addresses this by querying external knowledge bases before generating responses. The architecture consists of three components: a retrieval engine searches databases or document repositories, an embedding model converts queries and data into vector representations for semantic matching, and the LLM synthesizes retrieved information with existing knowledge.
RAG’s operational appeal is straightforward—organizations update databases rather than retrain models, ensuring real-time relevance with less effort. In retail, this means recommendations based on current inventory. In enterprise IT, policy systems reflect current rules without model retraining.
However, RAG reveals significant limitations in complex enterprise environments. The first critical constraint is the multi-source join problem. A pharmaceutical company case study illustrates this: the organization attempted centralized dashboards integrating clinical systems, sales platforms, and CRM software. RAG could find individual tables but struggled when queries crossed system boundaries. Questions like “Which products with above-median sales have the longest time-to-market?” required understanding relationships and business logic nowhere explicitly defined in either system.
The second limitation involves encoding implicit business logic. Enterprise systems embody subtle rules deeply embedded in operations. A healthcare system’s patient records contain implicit business rules about field validity in different contexts. A financial system tracks regulatory rules about account operations. RAG works from explicit schema information and documented descriptions—it cannot easily infer embedded business rules, leading to systematically incorrect answers.
Academic research documents substantial performance degradation when moving from benchmarks to real deployments. Models achieving 85% accuracy on Spider benchmark dropped to 52% accuracy on proprietary enterprise databases due to domain-specific terminology and schema heterogeneity. A production RAG system achieved 92.5% query validity by incorporating explicit business logic encoding—but this required substantial custom engineering beyond basic RAG components.
RAG also introduces computational costs at scale. Every query incurs retrieval overhead—searching embeddings, ranking candidates, preparing context. Cost analysis shows base models cost approximately $11 per 1,000 queries, while base models with RAG cost $41 per 1,000 queries due to context bloat. Every retrieved chunk inflates token consumption. Across thousands of users, this creates significant cost multipliers.
Latency creates critical issues for real-time environments like customer support chatbots or financial trading systems. Retrieval adds extra steps meaning responses take longer compared to purely generative models. Some teams experiment with hybrid techniques that pre-cache information, but these introduce additional complexity.
Finally, RAG faces persistent data quality challenges. If knowledge bases contain outdated or incorrect information, RAG reliably retrieves this bad information, potentially making hallucination problems worse. Knowledge bases can be perfectly formatted but semantically inconsistent, causing RAG to retrieve contradictory information. The research is clear: RAG is only as good as the data it retrieves from.
Fine-Tuning: When It Works, When It Breaks
Fine-tuning takes a fundamentally different approach by updating model parameters through training on domain-specific data. Developers prepare curated datasets—legal documents for law firm assistants, medical Q&A pairs for healthcare applications, customer support transcripts for service automation. The quality and relevance of this dataset directly determines fine-tuned model performance.
Benefits for specialized domains are well documented. Fine-tuned models achieve superior performance on targeted tasks, develop fine-grained understanding of domain terminology, and minimize drift in high-precision workflows like medical coding or financial reporting. A striking efficiency example shows a fine-tuned model matched GPT-3 performance on a task while being 1,400 times smaller—fundamentally transforming deployment economics.
However, reality in enterprise environments reveals significant challenges. The core problem: enterprises operate with noisy, inconsistent data by nature. Corporate datasets contain conflicting labels, policy exceptions, outdated templates, and user-generated artifacts violating clean-data assumptions. Research documents that even 10-25% incorrect data in fine-tuning sets dramatically degrades model performance and safety. A critical threshold exists: at least 50% of fine-tuning data must be correct for models to recover robust performance. Surprisingly, base models without any fine-tuning often outperformed almost all variants tuned on noisy data.
This creates the specialization paradox. As models are updated on broader data, performance on narrow, high-stakes tasks can degrade. A debt collection agent fine-tuned lightly for tone can become unstable computing compliant installment plans after base model refresh.
The second fundamental problem is catastrophic forgetting—where models forget previously learned information when trained on new tasks. Mechanistic analysis reveals this happens through coupled processes: gradient interference disrupts attention mechanisms, continued optimization induces representational drift in intermediate layers, and loss landscape flattening makes recovery of previous minima increasingly difficult. For smaller models, performance on initial tasks declines to approximately 55% after 2-3 subsequent fine-tuning steps.
Model drift presents another challenge—provider updates to base models change behavior of downstream fine-tuned systems. One study observed GPT-4 between March and June 2023 finding performance on tasks like identifying prime numbers dropped significantly over time. Domain-expert AI carefully calibrated can suffer performance degradation with every base model update.
For enterprises subject to privacy regulations like GDPR, fine-tuning introduces compliance risk. The “right to be forgotten” requires personal data removal from processing systems. Once data influences model weights through fine-tuning, removing that influence is technically difficult and often requires retraining. RAG makes this simpler—data can be purged instantly from indexes—whereas fine-tuning makes data lineage verification opaque.
Fine-tuning makes sense for stable, narrow specializations where data quality is controlled and continuous retraining is feasible. It excels when organizations need consistent tone, deep domain specialization, and lowest possible response latencies. Fine-tuning is inappropriate when data changes frequently, compliance requires transparent data lineage, or enterprises cannot guarantee high-quality training data.
Context Engineering: The Foundational Layer
Context engineering emerges from recognizing that both RAG and fine-tuning operate within a broader information architecture determining their success or failure. Where RAG retrieves external information and fine-tuning bakes knowledge into weights, context engineering is the discipline of designing how information flows through entire systems. This includes system instructions, conversation history, retrieved documents, available tools, business rules encoded as structured data, and real-time information from external services.
The distinction matters because most production AI failures are context failures, not model failures. When enterprises deploy sophisticated LLMs but constrain them with bloated context windows full of irrelevant information, models lose focus. Studies show that as context length increases, accuracy decreases—a phenomenon called context rot. Even models with 200K token windows experience degradation when critical information is buried in noise.
Research on this phenomenon shows that when LLMs answer questions with gold evidence present, fact-checking accuracy generally declines as context length increases. Evidence placement matters significantly: accuracy is consistently higher when relevant evidence appears near the beginning or end of prompts and lower when placed mid-context. If critical information is buried in the middle of long context, models may fail to use it even when correct and relevant.
Context engineering addresses this by treating context as a precious, finite resource requiring careful curation. The core principle: relevance, freshness, and coherence matter far more than completeness. Rather than attempting to include everything models might need, context engineering asks: “What is the minimal set of information enabling this model to reason correctly about this specific task?”
Context engineering operates across six distinct domains that must work together. First, system instructions and behavioral constraints define role, boundaries, and governance rules models must follow. Second, conversation history and user preferences maintain state across interactions ensuring coherence. Third, retrieved information from documents or databases, typically through RAG-like mechanisms but filtered for relevance. Fourth, available tools and their definitions, carefully curated to avoid overwhelming models. Fifth, structured output formats and schemas guiding models toward generating responses downstream systems can consume. Sixth, real-time data and external API responses ensuring current state information availability.
The power of context engineering becomes apparent examining how it enables sophisticated agent behavior. Traditional RAG systems work as pipelines: retrieve documents, append to prompt, generate response. Context engineering systems work as orchestrated information flows: understand current task and agent state, determine what information agents need for next action, fetch only that information just-in-time from appropriate sources, format for current reasoning stage, and inject precisely when most useful.
This matters because agents operate fundamentally differently from simple question-answering systems. An agent might check inventory levels, place orders, verify credit limits, and generate responses—all within single interactions. Poorly engineered context would pre-load all possible information overwhelming models. Well-engineered context provides just-in-time information: retrieve inventory only when agents decide to check it, fetch credit limits only when needed, format each piece for specific decisions agents are about to make.
Anthropic’s research emphasizes just-in-time context as opposed to pre-loading. Rather than pre-processing all relevant data upfront, agents maintain lightweight identifiers—file paths, stored queries, web links—and use these references to dynamically load data into context at runtime using tools. This mirrors human cognition: people don’t memorize entire corpuses but use external organization systems like file systems to retrieve relevant information on demand.
Context engineering also requires sophisticated memory management for long interactions. Customer support conversations spanning multiple sessions, sales cycles lasting weeks, or product troubleshooting requiring past interaction context all demand coherent state management. Three strategies address this: compaction summarizes old conversation turns while preserving decisions and unresolved issues; structured note-taking enables agents to maintain notes outside context windows pulling relevant information on-demand; tool result clearing removes raw outputs after processing freeing context for new information.
The infrastructure underlying context engineering differs substantially from basic RAG or fine-tuning. Organizations implementing context engineering build what is increasingly called a Context Engine or Context Platform—integrated infrastructure providing comprehensive, intelligent context assembly services for AI applications. This platform combines multiple components: knowledge graphs capturing relationships and implicit business logic, vector databases enabling semantic search, rules engines enforcing policy constraints, temporal databases tracking version control, and governance layers implementing role-based access controls.
The evolution toward context platforms reflects recognition that context quality, real-time nature, dynamic assembly capability, and productization level directly determine enterprise AI competitiveness. This is not about picking smarter models or more clever prompts. It’s about building infrastructure ensuring every AI system interaction provides the most accurate, current, appropriately contextualized information to solve specific problems at hand.
Data Quality: The Critical Foundation
Underlying both RAG and context engineering is an infrastructure problem that has become increasingly visible: data quality. The research community consensus is clear: no amount of model sophistication can compensate for weak data foundations. The Data, BI and Analytics Trend Monitor 2026 reclaimed data quality as the number one priority, with explicit recognition that “correct decisions can only be made on the basis of reliable, consistent data.” For AI specifically, “high data quality is more important than ever to avoid hallucinations, bias or faulty recommendations.”
This represents a significant shift. The machine learning industry operated for years under the belief that larger models with more sophisticated algorithms could be resilient to imperfect inputs due to scale. The opposite is proving true. The larger and more complex models become, the more sensitive they are to subtle inconsistencies and the more costly those inconsistencies become when replicated across automated processes.
The six dimensions of data quality framework provides structure for understanding what data quality means in RAG and AI contexts. Accuracy measures whether data correctly represents real-world entities—critical because inaccurate data leads directly to factual errors. Completeness ensures all required elements are present; incomplete data causes systems to generate responses based on partial context. Consistency maintains uniform data across sources; inconsistent data creates confusion when encountering conflicting information. Timeliness ensures data is current; outdated information causes obsolete recommendations. Validity confirms data conforms to defined formats; invalid data can cause retrieval errors. Uniqueness ensures each entity is represented once; duplicate records skew retrieval algorithms.
The practical impact of poor data quality in RAG systems is quantifiable. Organizations with high data quality achieve 95%+ factual accuracy with proper citations and high user trust. Those with poor data quality experience 60-70% accuracy with frequent contradictions and low trust leading to system abandonment.
A pharmaceutical case study illustrates this dynamic. Before implementing automated data cleaning, query validity hovered around 76.4% because underlying data contained schema violations, missing values, and entity mismatches. The system then implemented multi-stage data quality validation at four levels: source validation, transformation validation, loading validation, and runtime validation. This comprehensive approach improved query validity to 92.5%, schema compliance to 95.1%, and semantic accuracy to 90.7% while reducing query turnaround time by 99.1%.
Organizations treating data quality as continuous operational infrastructure rather than one-time cleanup gain substantial advantages. They employ observability and anomaly detection as first-class concerns, instrumenting pipelines end-to-end. They implement policy-as-code defining data contracts and SLA expectations. They establish cross-functional alignment embedding data engineers into product teams. These organizations report data quality maintenance costs that represent investments in reliability rather than taxes on incompetence.
Integrated Approaches: Building Production Systems
The question of whether to choose RAG, fine-tuning, or context engineering has become less relevant as production-grade enterprise systems converge on integrated approaches combining all three. The most effective strategy can be summarized as “behavior in weights, knowledge in context.”
This approach fine-tunes models on carefully curated data to establish consistent behavior—tone, output formatting, adherence to organizational standards, and safety constraints. Fine-tuning occurs on high-quality, relatively small datasets where curation is feasible. Once behavioral specialization is complete, organizations deploy fine-tuned models within context engineering frameworks that supply knowledge dynamically through RAG. A financial assistant might be fine-tuned to ensure professional tone while using RAG to fetch latest market indices. A healthcare assistant is fine-tuned to follow diagnostic reasoning patterns while RAG provides access to latest research.
This hybrid approach addresses weaknesses in each component. Fine-tuning alone creates brittleness because models eventually forget or drift. RAG alone struggles with specialized reasoning because general-purpose generators lack domain expertise. Context engineering alone cannot function without content to engineer—the engineered context must be generated by either fine-tuned models or augmented RAG systems.
Practical implementation requires careful attention to design principles. First is semantic clarity in system instructions—providing extremely clear language at the right altitude between hardcoding overly specific logic and providing so little guidance that models guess. Second is strategic use of examples—curating diverse, canonical examples that effectively portray expected behavior rather than stuffing edge cases. Third is just-in-time context retrieval over pre-loading, enabling progressive disclosure where agents incrementally discover relevant context.
Fourth is limiting tool complexity—research shows LLM performance degrades when given more than 5-10 tools per agent. Beyond this threshold, models experience analysis paralysis. When organizations have 20-30 tools available, the solution is implementing hierarchical agent structures where specialized agents handle specific domains.
Fifth is structured memory management for long interactions—implementing tiered memory strategies where recent critical information stays in active context, older but potentially relevant information is summarized in structured notes accessible on-demand, and processed information unlikely to be needed again is archived.
Sixth is continuous evaluation and monitoring—tracking retrieval accuracy, generation quality, hallucination rates, latency, and cost. Teams measure not just technical metrics but business outcomes: user satisfaction, task completion rates, decision-making quality, and whether systems deliver promised ROI.
Organizations implementing these best practices report measurable improvements. API costs decrease 40-70% through better context curation. Task completion rates improve 2-3x through better-engineered context. Inference latency decreases through elimination of unnecessary context processing. System reliability increases as fewer failures stem from context mismanagement rather than model limitations.
Strategic Implications for Enterprises
For enterprises with complex data integration requirements and high business stakes around AI-generated decisions, the future architecture is clear. Organizations should invest in context engineering as foundational infrastructure: comprehensive data governance, semantic metadata, business logic encoding, and just-in-time retrieval systems that can assemble context dynamically for specific tasks.
Within this context engineering framework, selective fine-tuning on high-quality, carefully curated data establishes consistent model behavior. RAG systems then provide current information grounded in verified sources. This integrated approach delivers the accuracy, reliability, and adaptability required for enterprise AI to move from proof-of-concept pilots to mission-critical systems generating measurable business value.
Promethium dramatically accelerates this path by tackling the context engineering challenge at scale. Rather than requiring teams to manually build and maintain context for every query, Promethium leverages existing enterprise metadata to dynamically construct context graphs at query time—assembling the right business logic, relationships, and semantics on the fly as questions come in. This collapses the cost and effort curve of context engineering, making it practical to go from pilot to production without linear increases in manual curation work.
The competitive advantage in enterprise AI is shifting from model sophistication to context engineering sophistication—the ability to architect systems ensuring every AI interaction provides accurate, current, appropriately contextualized information supporting reliable decision-making. Organizations recognizing this shift and investing accordingly in context infrastructure while building data governance as first-class concerns are establishing advantages grounded not in hype but in operational readiness.