Metadata Management for AI: Making LLMs Trust Your Data in 2026
Enterprise AI initiatives face a fundamental challenge: large language models generate confident answers from fragmented data contexts. Organizations invest heavily in modern data stacks, semantic layers, and AI infrastructure, yet most operate with metadata scattered across incompatible systems—data catalogs, BI tools, transformation platforms, and data warehouses that rarely communicate. This fragmentation creates a silent crisis where AI systems hallucinate not because models are flawed, but because they lack unified context to understand what enterprise data actually means.
The cost is quantifiable. Text-to-SQL systems achieve 86% accuracy on academic benchmarks but only 6% on actual enterprise databases when working with raw schemas alone. Organizations deploying AI without proper metadata foundations experience failure rates far exceeding public narratives, with knowledge workers spending 4.3 hours weekly verifying AI output and 47% making at least one major decision based on hallucinated content.
What does it take to deliver production-ready enterprise data analytics agents?
Read the complimentary BARC report
This guide examines how unified metadata management creates the foundation for trustworthy AI insights, with practical steps for aggregating technical and business context without massive integration projects.
The Five Layers of AI-Ready Metadata
Effective metadata management for AI requires understanding five distinct but interconnected layers that together provide complete context for accurate insights.
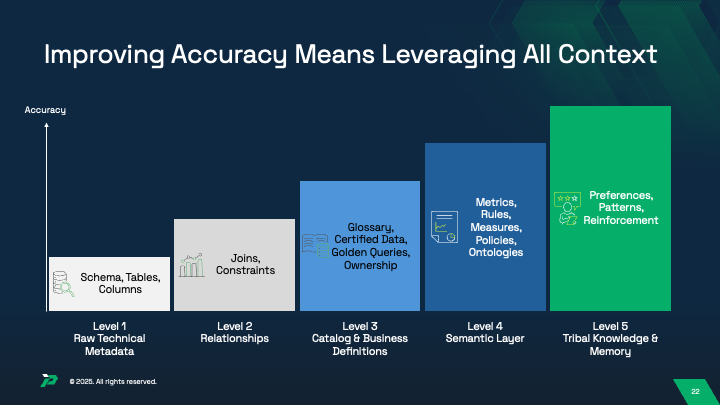
Layer 1: Raw Technical Metadata
Technical metadata forms the vocabulary through which LLMs construct queries. This includes database schemas, table structures, column definitions, data types, and basic constraints. However, raw schema information alone provides minimal value. Research shows that enterprise text-to-SQL accuracy deteriorates to 6% when LLMs receive only column names and data types, compared to 86% on standardized academic datasets.
The gap exists because enterprise databases contain hundreds of tables and thousands of columns. LLMs cannot determine which tables are relevant, what valid join paths exist, or how entities relate without explicit documentation. Technical metadata must include primary keys, foreign key constraints, cardinality rules, and valid join paths to be useful.
Layer 2: Relationships and Constraints
Adding relationship information—how tables connect through joins, one-to-many or many-to-many relationships, and referential integrity rules—improves LLM accuracy substantially. When organizations provide Level 2 context with technical metadata plus relationships, accuracy improves to 20-40%, a meaningful but still insufficient baseline.
The limitation is incompleteness. A schema showing that tables A and B can join on customer_id provides no explanation of what each table represents or how data flows between them. This is where business context becomes essential.
Layer 3: Catalog and Business Definitions
Business metadata transforms raw technical information into meaningful business concepts. This layer includes human-readable definitions of fields, business glossaries, metric calculations, certified data sources, golden queries, and ownership information. When organizations define terms like “active customer,” “net revenue,” or “churn rate” with explicit, standardized definitions, AI agents gain the ability to understand not just what data exists, but what it means.

What is a context graph and why are they the next evolution of context engineering?
Get your comprehensive guide now.
Adding Level 3 context pushes accuracy from 20-40% to 40-70%. Incorporating business context through semantic catalogs improved SQL generation accuracy by up to 27% on otherwise identical database schemas. The precision of these definitions matters significantly. When one team defines “revenue” as gross sales while another subtracts discounts and returns, LLMs receive contradictory signals, leading to confidently incorrect responses.
Layer 4: Semantic Layer Intelligence
The semantic layer consolidates metrics, business rules, measures, access policies, and ontologies into a unified framework. Unlike basic business definitions, semantic layers provide complete calculation logic, dimensional hierarchies, and context-aware metric interpretation.
However, semantic layers deliver benefits only when integrated with AI retrieval systems. Many organizations implement semantic layers for BI tool consistency but don’t expose semantic layer metadata to AI agents operating outside BI tools, causing agents to revert to inferring metric definitions from raw schema.
Layer 5: Tribal Knowledge and Memory
The final layer captures preferences, usage patterns, query history, and human reinforcement signals. This includes which dashboards executives view weekly, which queries consume significant compute resources, and which data interpretations have been validated by subject matter experts.
Organizations implementing Level 5 context—combining all previous layers with agentic memory and human reinforcement—achieve 90%+ accuracy necessary for production deployment. The progression is not linear; successful organizations implement all five layers working together, not individual components in isolation.
Quantifying the Cost of Metadata Fragmentation
Metadata fragmentation manifests in quantifiable accuracy losses with serious business consequences.
The Text-to-SQL Accuracy Gap
While leading language models achieve 85-90% accuracy on standardized benchmarks, the same models deliver only 10-31% accuracy on production enterprise schemas. This represents not a model failure but a context failure.
The degradation follows a predictable pattern. Systems with only raw schema information achieve 10-20% accuracy. Adding relationship information improves this to 20-40%. Integrating business definitions advances accuracy to 40-70%. Organizations implementing semantic layers report 70-85% accuracy. Reaching 90%+ requires tribal knowledge encoded through feedback loops, historical query patterns, and persona-specific interpretations.
In one documented case, an organization deployed a text-to-SQL system with only schema-level metadata. The system confidently returned incorrect answers to basic business questions because it misunderstood which tables should be joined, applied incorrect filters, and made wrong assumptions about aggregation rules. Users acted on hallucinated answers, leading to incorrect business decisions discovered weeks later.
Retrieval-Augmented Generation Failures
RAG systems frequently fail to deliver expected accuracy improvements when organizations dump large volumes of unfiltered, uncontextualized documents into model context windows. Research demonstrates that LLMs actually perform better with fewer, more precisely targeted documents. In one benchmark study, model accuracy dropped nearly 20% when presented with 30 documents compared to 5 documents, even when all documents were retrieved by semantic similarity.
Systems operating without proper metadata context report faithfulness rates as low as 60-70%. The difference hinges on whether the system can distinguish relevant from irrelevant context—a capability depending entirely on metadata quality.
Documented Business Impact
A major technology company’s customer service chatbot, operating without proper metadata about product specifications and pricing, confidently provided incorrect information to customers. The company ultimately had to honor incorrect pricing offers, resulting in significant financial losses. In another case, an AI-powered sales intelligence system lacking proper metadata about customer relationship definitions generated recommendations based on outdated information, leading to wasted sales effort and missed opportunities.
IBM research indicates that organizations deploying AI initiatives without proper data quality foundations experience failure rates far exceeding the public narrative. When organizations implement proper data governance and comprehensive metadata management before deploying AI systems, project success rates improve dramatically.
The Enterprise Metadata Fragmentation Crisis
Organizations in 2026 face a fundamental architecture problem: metadata is fragmented across multiple specialized systems, each optimized for a specific purpose, and none communicating reliably with the others.
The Scope of Fragmentation
The average enterprise operates 371 SaaS applications, and data flows through many of these systems in ways traditional integration approaches cannot capture. Metadata about data assets exists in multiple forms: technical metadata in data warehouse information schemas, business metadata in data catalogs, semantic metadata in BI tools, transformation metadata in dbt or other frameworks, and operational metadata in monitoring platforms.
A concrete example illustrates the problem. Consider an organization with customer data flowing through multiple systems. The data warehouse schema defines a table “customers” with column “status” containing values like “active,” “dormant,” or “churned.” The data catalog documents the same field differently: “customer_status represents engagement level based on transaction frequency in last 90 days.” The BI tool implements a slightly different version, defining “status” based on subscription validity. The dbt semantic layer defines an entirely different metric: “active_customers = customers with at least one transaction in the last 30 days.” LLMs attempting to answer questions about active customers receive contradictory signals from these different metadata sources, making hallucinations virtually inevitable.
Organizations implementing data mesh architectures report that metadata fragmentation actually worsens without proper governance infrastructure. When each domain team implements their own metadata practices without standardization, the enterprise loses the ability to understand how datasets relate to one another. The data mesh market is growing at 16.3% CAGR, expanding from $1.28 billion in 2023 to projected $4.27 billion by 2031, yet without unified metadata management, this decentralization creates integration nightmares for AI systems operating across domain boundaries.
Why Fragmentation Persists
Each tool in the modern data stack was designed for a specific use case and optimized for a specific user persona. Data catalogs prioritize discovery and lineage visualization for data analysts. Semantic layers prioritize consistent metric definition for business analysts. BI tools prioritize report-level metadata and dashboard context. None of these tools was designed as an AI context engine.
The governance challenge compounds the problem. Organizations implementing data governance typically create policies in one tool—often a data catalog—but struggle to propagate those standards to other systems. A data owner might tag a dataset as “sensitive” in the catalog, but that designation might not propagate to the semantic layer, the BI tool, or downstream AI systems, creating inconsistent governance enforcement.
Tool-Specific Integration Challenges
Data catalogs like Collibra and Alation manage comprehensive metadata about data assets, including lineage, quality metrics, ownership, and business definitions. However, catalogs traditionally operate on a pull model, extracting metadata from source systems on a schedule rather than capturing changes in real time. When a database schema changes or transformation logic is updated, the catalog might not reflect that change for hours or days, creating stale metadata AI systems cannot rely on.
Semantic layers like dbt’s Semantic Layer or Looker enable consistent metric definition and business logic documentation. However, these tools optimize for specific use cases—dbt emphasizes transformation logic while Looker emphasizes BI metric definition—rather than providing comprehensive metadata for arbitrary AI queries. Integration between semantic layers and data catalogs remains manual in most cases.
BI tools like Power BI, Tableau, and Looker store valuable metadata about reports and dashboards, but this metadata typically remains isolated within the BI tool, not accessible to AI systems operating outside the BI platform. Organizations attempting to build comprehensive data lineage discover that BI tool metadata is often locked within proprietary formats or requires custom connectors to extract.
Technical Barriers to Metadata Aggregation
Organizations attempting to unify metadata encounter substantial technical barriers preventing straightforward integration.
API and Integration Limitations
Most metadata tools expose incomplete or inconsistent APIs that make aggregation difficult. Data catalogs offer REST APIs for querying metadata, but these APIs often reflect the catalog’s internal data model rather than providing a standardized interface aligned with how data is actually structured in source systems. When organizations attempt to integrate catalog metadata with semantic layer metadata, they discover the two systems often model the same concepts differently.
BI tools present particular challenges. Power BI, Tableau, and Looker each expose metadata through proprietary APIs designed for their specific platforms. Extracting lineage metadata from Power BI requires specialized connectors that attempt to parse internal data model definitions. Organizations with multi-vendor BI environments often find themselves maintaining separate metadata integration pipelines for each tool.
Conflict Resolution in Lineage Metadata
When organizations implement automated metadata extraction from multiple sources, they frequently discover that sources report different lineage for the same data assets. A BI tool might show that a dashboard is built from Table A. A data catalog might show the dashboard queries a view built from Tables A and B. A transformation tool might show the view is actually built from Tables B and C. Without automated conflict resolution, metadata aggregation produces a confusing, unreliable picture.
Solutions require AI-powered reconciliation layers that ingest lineage from multiple sources, detect conflicts, and apply logic to determine the correct path. Implementing such reconciliation is technically complex, requiring understanding not just lineage claims themselves, but the relative reliability and comprehensiveness of each source.
Real-Time Metadata Capture
Traditional batch-oriented metadata extraction approaches cannot support modern AI systems that need current context. When an LLM receives a question depending on recently changed data, it needs to know that change has occurred. However, most metadata catalogs update their metadata on schedules ranging from hourly to daily, creating gaps where stale metadata is actively served to systems.
Real-time metadata capture requires event-driven architecture where schema changes, transformation updates, and job executions automatically trigger metadata extraction and propagation. Implementing this requires integration with event streams or change data capture systems, creating new dependencies in the architecture. The proliferation of different integration requirements means that real-time metadata extraction typically requires custom development per data platform.
Solutions for Unified Metadata Management
Organizations addressing metadata fragmentation have converged on several architectural approaches enabling unified metadata management without requiring complete tool replacement.
Active Metadata and Metadata-Driven Architecture
Leading organizations are moving toward “active metadata“—metadata that continuously updates and actively drives system behavior. Rather than treating metadata as documentation humans consult, active metadata becomes operational intelligence that systems rely on to make autonomous decisions. When metadata indicates a dataset contains PII, data access controls automatically apply based on that metadata. When metadata indicates a transformation has failed quality checks, dependent queries are automatically routed to alternative data sources.
Organizations implementing active metadata approaches report substantially improved AI reliability. Active metadata platforms continuously monitor data quality and schema changes, updating metadata in real time as systems evolve. This enables AI agents to operate with current context rather than stale metadata.
Semantic Layers as AI-Ready Metadata Infrastructure
Semantic layers have evolved from business intelligence tools into foundational metadata infrastructure serving both BI tools and AI agents. The dbt Semantic Layer and similar platforms enable organizations to define business metrics and entity relationships once, in version-controlled code, and make those definitions available to multiple downstream tools through standardized APIs.
Organizations implementing semantic layers as part of broader metadata management achieve substantial improvements in AI accuracy. By ensuring every data tool—whether BI, AI agent, or analytics platform—operates from the same metric definitions, organizations eliminate a major source of confusion and hallucination. However, semantic layers realize their full value only when integrated with data catalogs and lineage systems.
Unified Metadata Control Planes
A recent architectural pattern involves implementing “metadata control planes”—unified metadata management platforms that orchestrate metadata from multiple source systems and serve that metadata through consistent APIs to downstream consumers. Rather than attempting to replace existing tools, metadata control planes integrate metadata from data catalogs, semantic layers, BI tools, transformation tools, and quality monitoring platforms, harmonize it into a common model, and expose it through standardized interfaces.
The Promethium Approach to Unified Context
Promethium’s 360° Context Hub directly addresses the metadata fragmentation challenge by automatically aggregating metadata from data catalogs, BI tools, semantic layers, and data sources into a unified layer that AI agents can query. The architecture follows the five-layer metadata model, capturing raw technical metadata from schemas, relationships from constraints and joins, business definitions from catalogs and glossaries, semantic layer metrics and rules, and tribal knowledge through agentic memory and human reinforcement.
The Context Hub continuously ingests metadata from multiple sources, reconciles conflicts using AI-powered logic, and serves unified context through APIs supporting both traditional SQL access and LLM integrations. When Mantra, Promethium’s Data Answer Agent, receives a natural language question, it leverages the complete context to generate accurate queries, apply appropriate business rules, and deliver explainable answers with full lineage.
This approach enables organizations to preserve existing investments in data catalogs, semantic layers, and BI tools while providing AI agents with the unified context they require. Rather than forcing metadata consolidation into a single tool, Promethium aggregates context from wherever it exists, creating a comprehensive view without disrupting established workflows.
Implementation Roadmap
Organizations implementing unified metadata management typically follow a phased approach beginning with understanding current metadata maturity.
Phase One: Metadata Audit and Assessment
Successful organizations begin by conducting comprehensive audits of their existing metadata landscape. This includes identifying what metadata exists in each system, understanding what metadata is missing, assessing metadata quality and consistency, and documenting integration dependencies. This audit reveals fragmentation patterns—typically, organizations discover that similar concepts are defined differently across systems, that ownership is ambiguous across multiple platforms, and that critical metadata exists in some systems but not others.
The audit phase also establishes baseline metrics. Organizations measure time-to-discover for typical data questions, track how often users bypass formal metadata systems, and quantify compliance gaps. These baseline metrics become critical for demonstrating return on investment.
Phase Two: Identify High-Value Metadata Domains
Rather than attempting to unify metadata across all systems simultaneously, successful organizations identify 3-5 high-value domains where unified metadata delivers immediate value. For many organizations, these domains focus on revenue, customers, and products. For healthcare organizations, domains might focus on patients, treatments, and outcomes.
Focusing on high-value domains enables organizations to implement unified metadata rapidly and demonstrate value that builds organizational support for broader implementation. A 90-day implementation targeting critical domains can establish unified metadata for revenue metrics, customer definitions, and product hierarchies—enough to significantly improve AI accuracy for the majority of business questions in those domains.
Phase Three: Implement Metadata Aggregation Layer
Organizations implement metadata aggregation infrastructure that pulls metadata from existing systems for those domains. This involves implementing custom ETL logic to extract metadata from data catalogs, semantic layers, BI tools, and transformation platforms. For organizations using unified platforms, this might involve leveraging native integration capabilities.
The aggregation layer should normalize metadata from different sources into common models. When “customer_id” is defined as “customers.id” in the schema, “cust_id” in the BI tool, and “customer_key” in the data warehouse, the aggregation layer should recognize these as the same entity and maintain links between them. This normalization enables downstream AI systems to understand that different systems are referencing the same concept even when naming differs.
Phase Four: Expose Unified Metadata Through APIs
Unified metadata delivers value only when AI agents and other systems can reliably access it. Organizations should implement standardized APIs that expose aggregated metadata in forms that downstream systems can consume. These APIs should provide semantic search, lineage traversal, quality signals, and ownership context.
Organizations increasingly leverage OpenLineage standards and metadata APIs to enable integration with downstream tools. By adopting standards-based metadata exposure, organizations reduce custom integration effort and increase the likelihood that new tools can integrate with metadata infrastructure without custom development.
Phase Five: Implement Governance and Quality
Unified metadata is valuable only to the extent that it is accurate and up-to-date. Organizations implement governance policies that define what metadata should be maintained, standards for metadata quality, and responsibilities for metadata curation. Rather than attempting to curate all metadata manually, leading organizations implement automated metadata capture combined with human-in-the-loop validation for critical metadata.
Metadata governance should establish clear ownership. Data stewards or domain experts should be assigned responsibility for ensuring metadata accuracy in their domains. By combining automation with human oversight, organizations achieve high-quality metadata at scale.
Measuring Success
Organizations implementing unified metadata management should track specific metrics demonstrating value:
AI Accuracy Improvements: Measure text-to-SQL accuracy, RAG faithfulness rates, and hallucination frequency before and after metadata unification. Target 90%+ accuracy for production AI systems.
Time-to-Insight Reduction: Track how long it takes to answer typical business questions. Organizations report 10x improvements, reducing response times from days to minutes.
Productivity Gains: Track decrease in manual data pipeline development requests.
Governance Compliance: Monitor policy enforcement consistency across systems. Measure reduction in compliance violations and security incidents.
User Adoption: Track self-service data access rates and reduction in IT escalations. Measure business user satisfaction with AI-generated insights.
Conclusion
As enterprise AI deployment accelerates through 2026, metadata management has transformed from a data governance concern to a foundational requirement for AI reliability. Organizations that fail to unify metadata across catalogs, semantic layers, and BI tools will continue experiencing high hallucination rates, low user trust, and inability to move AI initiatives from pilot to production.

Why are context graphs the missing link for agentic systems?
Get your complimentary copy of the latest Gartner report now.
The path forward is clear: treat metadata not as documentation but as operational intelligence that drives AI behavior. Invest in aggregating metadata from multiple sources into coherent, unified models. Implement governance ensuring metadata remains accurate and current. Design AI retrieval systems to actively consume and leverage rich metadata context.
The technical barriers to unifying metadata are real but surmountable. Leading organizations have demonstrated that comprehensive metadata aggregation is achievable without wholesale tool replacement. The competitive advantage accruing to organizations that successfully implement unified metadata management will prove substantial—these organizations will deploy AI systems that generate trustworthy answers, reduce hallucinations, and deliver measurable business value.