

Why It’s Time to Rethink How Data Teams Deliver Answers
Self-service is everywhere. In our personal lives, we expect instant access — whether it’s booking a flight, moving money, or getting directions. But inside the enterprise, self-service remains frustratingly out of reach, especially when it comes to data.
Despite years of investment in data platforms, dashboards, and analytics tooling, most organizations still struggle to answer basic questions without manual intervention from a data team.
The best we’ve been able to achieve is self-service analytics: business users slicing and dicing pre-approved datasets using tools like Power BI, Tableau, or Looker. But the moment the data isn’t there — or the question requires new logic, joins, or sources — the process breaks.
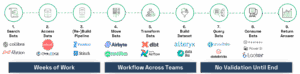
Every new request flows back to the data team. And not just one person — engineers must build or update pipelines, analysts must locate and prepare the right data, and someone has to validate and package it all for consumption. This cross-functional effort often takes days or weeks, creating a bottleneck that slows decisions and undermines agility. It’s also the number-one reason AI initiatives stall and analytics programs fail to scale.
It’s time to rethink self-service.
Self-service shouldn’t mean offloading work to the business. It should mean empowering data and analytics teams to deliver trusted answers faster — across all data, without complex wrangling or risky shortcuts.
That’s what we mean by self-service data: enabling trusted, contextual answers — instantly, across all your data — without overloading your team.
In this post, we’ll explore:
- Why self-service analytics is not enough
- What self-service data really means — and why enterprises need it
- Common misconceptions that create confusion
- What capabilities are required to make it work
- Why this shift is essential for scaling AI and delivering value from enterprise data
Let’s get into it.
What is Self-Service Data?
Self-service data is an approach that enables trusted, contextual answers instantly across all enterprise data — without manual intervention from data teams for every request.
Unlike traditional data access models that require custom pipelines, ETL processes, or pre-built dashboards for each new question, self-service data provides governed access to all organizational data sources in real time. It combines the speed of direct data access with the trust and context that enterprises require.
Key Characteristics of Self-Service Data:
Instant Access: Answers are generated on-demand across all data sources without waiting for new pipelines or models to be built.
Contextual Intelligence: Every answer includes business context, data lineage, and semantic meaning — not just raw numbers.
Governed by Design: Data teams maintain control over security, quality, and definitions while enabling broader access.
AI-Ready: Provides the real-time, high-quality data foundation that modern AI initiatives require to succeed.
Self-service data doesn’t replace data teams — it amplifies their impact by shifting their role from manual provisioning to strategic enablement. The result is faster decisions, more successful AI deployments, and the ability to answer business questions that were previously impossible or prohibitively expensive to explore.
Why Self-Service Analytics Isn’t Enough
Self-service analytics was supposed to be the solution. Give business users a dashboard or dataset, and let them answer their own questions. In theory, it reduces dependence on the data team and accelerates decisions.
In reality, it only works when the right data is already available — and the questions are already known.
Here’s where it falls short:
- It assumes the data already exists in the right format: Dashboards are built on predefined models and curated datasets. If the question involves a different time frame, join, metric, or source, the user hits a wall. There’s no way to explore beyond what’s been pre-approved.
- It breaks when questions change: The moment a new initiative arises — a shift in product strategy, a sudden performance dip, a fresh regulatory request — analytics teams are flooded with ad hoc requests they can’t answer through existing dashboards. These require new data combinations, logic, and validation, which means going back to engineering and starting the process from scratch. As a result, ¾ of all data teams spend 50%+ of their time on ad hoc requests.
- It pushes the burden onto the wrong teams: Rather than empowering the data team, self-service analytics often sidesteps it. Business users are expected to find data, interpret it, and make decisions — without full context, lineage, or consistency. This leads to errors, misinterpretations, and trust issues.
- It doesn’t scale across the enterprise: Every department ends up building its own dashboards, definitions, and logic. What starts as “self-service” becomes siloed, fragmented analytics that are hard to govern and impossible to align across the business. Companies report that the majority of their dashboards get looked at either once or twice over their entire lifecycle.
- It’s not built for AI: AI requires real-time access to high-quality data — often across multiple systems and domains. Dashboards can’t provide this. They’re static, visual summaries for human consumption, not dynamic pipelines for AI agents or workflows.
In short: self-service analytics is a step — but not the final one.
To truly scale insights, support AI, and empower decision-making, organizations need something more powerful: self-service data.
What Self-Service Data Really Means
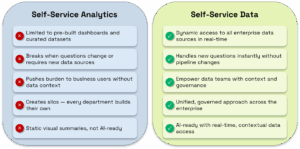
Self-service data goes beyond just dashboards and BI tools, but it isn’t about giving everyone direct access to raw datasets or complex tools. It’s about giving data teams the power to deliver answers faster and more confidently — without compromising control, context, or consistency. Here’s what defines self-service data in the modern enterprise:
- It includes all your data
Self-service data must reflect the complexity of real-world data environments. That means going beyond one platform or data lake. Self-service data connects to all your enterprise data — regardless of source, location, or format — without requiring everything to be moved or copied first. Whether data lives in Snowflake or Databricks, on-prem systems, or a legacy ERP, in a world where the average enterprise deploys 900+ apps and 15+ data platforms, it should be accessible in real time to answer the question at hand. - It delivers answers with context
Access alone isn’t enough. What makes data useful is context: knowing what it means, where it came from, and how it’s been used before. Self-service data incorporates lineage, semantic definitions, domain knowledge, and historical usage — so the answers that teams receive are not just accurate, but also explainable and aligned with business understanding. This is essential for building trust and ensuring AI-ready data across the organization. - It’s collaborative by design
Most business questions evolve as you explore the data. Static dashboards or one-off queries don’t support this. Self-service data supports conversational workflows — enabling analysts and data teams to clarify intent, iterate quickly, and refine questions in real time. Whether through natural language or low-code interfaces, the experience is interactive, intuitive, and fast, reducing the friction that typically slows down ad hoc analytics. - It works with the tools you already use
Self-service data should integrate into your existing stack and workflows. That means answers can be consumed in a plethora of tools: Power BI, Tableau, Databricks, Excel, or wherever else your teams already operate. There’s no need to reinvent your environment. Instead, self-service data fits into it — pushing the right results to the right tools at the right time, so teams can take action without switching contexts or disrupting their flow. - It empowers data teams — not bypasses them
Self-service data does not mean handing the keys to the business and hoping for the best. It means enabling data teams to say “yes” more often — without burning out or sacrificing standards. By automating tedious provisioning tasks and enriching answers with the necessary context, self-service data lets data engineers, analysts, and architects retain control, enforce governance, and deliver value faster. The result is scalable agility: more questions answered, more trust maintained, and more impact delivered.
Together, these principles define what self-service data should look like: fast, flexible, and trustworthy. It’s not about giving up control — it’s about designing a system where data teams stay in charge, but can deliver value at speed and scale. When self-service is done right, it doesn’t just accelerate answers. It strengthens alignment, boosts confidence, and sets the foundation for AI that actually works.
Common Misconceptions About Self-Service Data
Self-service data is a loaded term for executives and teams. As a result, it invokes many (outdated) mental models — especially the idea that dashboards alone are enough. Let’s break down five of the most common misconceptions:
- Self-service data means giving business users direct access to raw data.
This is one of the biggest myths. Giving business users raw access creates risk, not agility. Most don’t have the tools or training to work with complex datasets — and without proper context or governance, the risk of misinterpretation or misuse skyrockets. Self-service data isn’t about cutting out the data team; it’s about making the data team faster and more scalable. - Dashboards = self-service.
Dashboards are helpful for monitoring known metrics, but they don’t answer new questions or support real exploration. True self-service data goes beyond static views. It enables dynamic, ad hoc inquiry — even when the data hasn’t been modeled yet — by guiding users to the right data and logic based on intent and it is adaptable to the use case. - More access = less control.
It’s easy to assume that opening up data means losing control. But with the right approach, you can expand access and strengthen governance. Self-service data keeps the data team in the loop as the gatekeepers of trust — ensuring every answer is accurate, explainable, and secure. - It only works if everything lives in the same platform.
Many tools claim to support self-service — but only if all your data is moved into their ecosystem. That’s not realistic for most enterprises. A true self-service approach works across distributed, heterogeneous environments without requiring data duplication or lock-in. - It’s only for business users.
Self-service data is often framed as a tool for business users. But the real opportunity is in enabling data teams — analysts, analytics engineers, data product owners — to respond to requests faster, automate repeat work, and focus on higher-value analysis. It’s not about replacing them. It’s about amplifying their impact.
Understanding and addressing these misconceptions is the first step toward building a self-service data strategy that’s scalable, trusted, and truly transformative — not just for business users, but for the data teams who support them.
Why This Is Mission-Critical for AI and Real-Time Workflows
Self-service data isn’t just a convenience — it’s a critical foundation for AI and real-time decision-making. As Gartner reports, 60% of AI initiatives are destined to fail due to poor data practices.
Modern business questions don’t wait. Executives want to know what’s happening right now, not in a few weeks after a new pipeline is built. AI agents are only as good as the data they can access. And frontline decisions — from fraud prevention to dynamic pricing — depend on fresh, trustworthy insights delivered instantly.
But most data architectures still rely on batch pipelines, brittle integrations, and predefined dashboards. These weren’t designed for the pace of today’s business — or the complexity of AI.
If your data still has to be moved, modeled, or approved before it can be used, AI fails. It hallucinates. It delivers incomplete answers based on outdated snapshots. That’s why context, governance, and speed are no longer nice-to-haves — they’re prerequisites for making AI work.
Self-service data fixes the root problem by:
- Giving AI systems governed access to real-time data across the enterprise
- Ensuring that answers come with business context, metadata, and lineage
- Enabling interactive refinement and explainability for both humans and agents
In short: You can’t scale your AI initiatives if you haven’t first scaled how questions get answered. Self-service data is the unlock — not just for humans, but also for machines.
From Gatekeeper to Enabler
For years, the data team’s role has been defined by control — building the pipelines, validating the data, protecting quality and governance. But that role has become a double-edged sword. The more the business depends on data, the more every question flows through a narrow, overloaded gate.
That’s no longer sustainable.
Self-service data offers a new model: one where data teams can stop reacting to every request and start enabling answers at scale. They’re still the stewards of trust, security, and quality — but they don’t need to be the bottleneck.
With the right foundation, data teams can:
- Define the guardrails while allowing faster access
- Focus on modeling and governance instead of manual provisioning
- Support thousands of questions with confidence and consistency
This is a shift from “build the pipeline” to “enable the answer.”
And when done right, self-service data creates something more powerful than a dashboard or a dataset. It enables what we call Data Answers — context-rich, instantly generated responses that are accurate, explainable, and ready for use across analytics, AI, or operations. We’ll dive into what makes a Data Answer and why it is a better, more flexible approach, in one of our next blogs.
That’s the future. And it’s already happening. With self-service data, data teams no longer need to choose between speed and trust — they can deliver both, and do it at scale. If you are curious about how your team can enable self-service data, reach out to our team to learn more.


