
Your organization has spent years aggregating data into warehouses, lakes, and clouds. Data engineers move terabytes daily. Governance teams catalog assets. BI teams build semantic models. Yet when you deploy AI agents to “talk to your data,” accuracy barely exceeds 20%.
The problem isn’t the data. It’s the context.
Just as data is fragmented across systems, context is fragmented across schemas, catalogs, BI tools, and analyst heads. Technical metadata lives in databases. Business definitions live in catalogs. Calculation logic lives in BI tools. Tribal knowledge lives nowhere systematically. AI systems need all of it — unified, synchronized, and accessible in real-time.
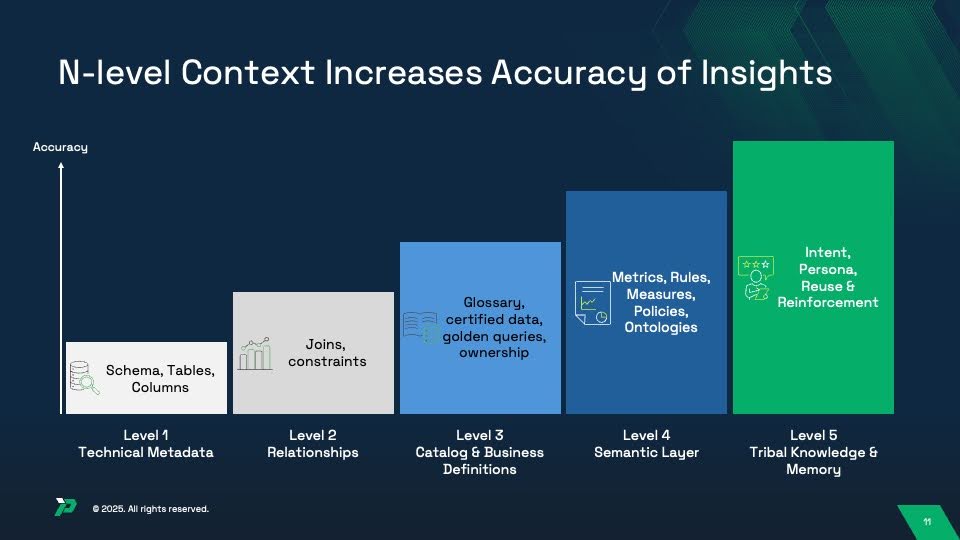
This is why context engineering is emerging as the new discipline alongside data engineering. Organizations that systematically capture and unify five levels of context achieve 94-99% AI accuracy. Those that leave context fragmented struggle at 10-20%.
This guide explains the five-level context architecture that determines AI analytics accuracy, where each level typically lives in enterprise systems today, and why the manual domain-by-domain approach to context building doesn’t scale.

Read the trend report to learn more about the latest advances in text-to-sql technology
The Context Fragmentation Problem
Before discussing the five levels, let’s understand why context fragmentation breaks AI analytics.
Data Integration Success, Context Integration Failure
Over the past decade, enterprises mastered data integration. Modern data stacks aggregate data from hundreds of sources into centralized platforms. ETL pipelines run continuously. Data lakes hold petabytes. Real-time streaming keeps everything current.
But context didn’t follow. Context remains distributed:
In your database schemas: Table structures, column names, data types (Level 1: Technical Metadata)
In your data models: ER diagrams, join paths, cardinality rules (Level 2: Relationships)
In your data catalog: Business glossaries, column descriptions, certified datasets (Level 3: Business Definitions)
In your BI tools: Metric definitions, business rules, fiscal calendars (Level 4: Semantic Layer)
In analyst heads: Query patterns, persona preferences, tribal knowledge (Level 5: Memory & Learning)
Each system maintains partial context. None talk to each other systematically. When AI agents query data, they lack the unified context needed to interpret it correctly.
Why AI Fails Without Unified Context
Consider a simple question: “What’s our Q4 revenue?”
Level 1 provides: A revenue column exists in the transactions table
But Level 1 doesn’t know:
- Which other tables to join for complete revenue picture (Level 2)
- That “revenue” means net revenue excluding refunds (Level 3)
- That Q4 means fiscal Q4, not calendar Q4 (Level 4)
- That when the CFO asks, they want recognized revenue, not bookings (Level 5)
Without all five levels unified, AI generates queries that are syntactically correct but semantically wrong. The answer appears correct — until someone validates it and discovers it’s off by 15%.
This pattern repeats thousands of times daily across enterprises deploying AI analytics. Not because the AI is broken, but because the context architecture is incomplete.
What Is Context Engineering?
Context engineering is the systematic practice of capturing, organizing, unifying, and maintaining the information AI systems need to interpret data correctly.
While data engineering focuses on moving and transforming data, context engineering focuses on aggregating meaning, relationships, logic, and knowledge that make data interpretable.
The Parallel to Data Engineering
| Data Engineering | Context Engineering |
|---|---|
| Extract data from sources | Extract context from sources |
| Transform data to consistent formats | Transform context to unified models |
| Load data into warehouses/lakes | Load context into unified layers |
| Maintain data pipelines | Maintain context synchronization |
| Ensure data quality | Ensure context completeness |
| Monitor data freshness | Monitor context accuracy |
Just as data engineering became essential in the 2010s for business intelligence, context engineering is becoming essential in the 2020s for artificial intelligence.
Why Context Engineering Matters Now
Three forces converge to make context engineering critical:
1. AI Adoption at Scale
Organizations are deploying AI agents across functions — customer service, sales, operations, finance. Each needs accurate, contextual data access. Manual context building can’t keep pace with AI deployment velocity.
2. LLM Context Window Limitations
Even 128K token windows can’t hold enterprise schemas. Context engineering determines what information LLMs receive — making the difference between 20% and 94% accuracy.
3. Cost of AI Errors
Incorrect AI-generated insights inform strategy, operations, and customer interactions. A 20% accurate system is worse than no system — it appears to work while delivering wrong information. Context engineering is risk management.
The Five Levels of Context Architecture
Let’s examine each level in detail: what it contains, where it typically lives today, why AI needs it, and how to capture it.
Level 1: Technical Metadata (Foundation)
What It Contains:
- Database schemas (tables, columns, views)
- Data types and constraints
- Table statistics (row counts, size, last update)
- Basic column-level metadata
Where It Lives Today:
- Database information schemas (Snowflake, Databricks, Oracle, PostgreSQL)
- Data warehouse system tables
- Cloud platform metadata services (AWS Glue, Azure Purview)
Why AI Needs This:
- Prevents hallucination of non-existent tables/columns
- Understands data structure and organization
- Identifies available data sources
- Knows data types for proper handling
Accuracy Impact: 10-20% (can see structure but lacks understanding)
Capture Strategy:
Most organizations already have this — it’s inherent in databases. The challenge is aggregating it across distributed sources. Databases expose metadata through information schemas, system tables, and APIs.
Example Technologies:
- Snowflake INFORMATION_SCHEMA
- Databricks DESCRIBE commands
- AWS Glue Data Catalog
- Azure Purview
- Google Cloud Data Catalog
Common Gaps:
- Undocumented or poorly named columns (
col1,field_a) - Missing statistics on data quality or completeness
- No description fields populated
- External data sources not cataloged
Level 2: Relationships (Join Paths & Constraints)
What It Contains:
- Primary keys and foreign keys
- Valid join paths between tables
- Referential integrity constraints
- Cardinality rules (one-to-many, many-to-many)
- Bridge table logic
Where It Lives Today:
- ER diagrams (often in documentation, not systems)
- Data modeling tools (Erwin, ERStudio, Lucidchart)
- Database foreign key constraints (often not enforced)
- Data vault or dimensional model documentation
Why AI Needs This:
- Eliminates hallucinated joins between unrelated tables
- Prevents many-to-many explosion errors
- Identifies correct join keys
- Understands data hierarchy and relationships
Accuracy Impact: 30-40% (correct structure and relationships, but no business meaning)
Capture Strategy:
This is where many organizations have significant gaps. Foreign keys are often not enforced in databases for performance reasons, so relationship knowledge lives in analyst heads or ERDs that aren’t system-readable.
Context engineering requires making relationship metadata programmatically accessible — importing ERDs into knowledge graphs, documenting join paths in data catalogs, or creating explicit relationship tables.
Example Technologies:
- Data modeling tools: Erwin, ER/Studio
- Data catalogs with lineage: Alation, Collibra, Atlan
- dbt with relationship definitions in YAML
- Knowledge graphs encoding entity relationships
Common Gaps:
- Relationships documented in PDFs or Visio, not machine-readable
- Implicit joins known only to senior analysts
- Complex bridge table logic not formalized
- Historical relationship changes not tracked
Level 3: Catalog & Business Definitions (Governance Layer)
What It Contains:
- Business glossaries mapping technical to business terms
- Column-level business descriptions
- Data ownership and stewardship assignments
- Certified datasets and trusted data sources
- Golden queries showing validated patterns
- Domain taxonomies and categorization
- Data quality scores and certification status
Where It Lives Today:
- Data catalogs: Alation, Collibra, Atlan, Informatica, Unity Catalog, Purview
- Governance tools and wikis
- Confluence/SharePoint documentation
- Spreadsheets maintained by data governance teams
Why AI Needs This:
- Maps business language to technical column names
- Disambiguates terms with multiple meanings
- Identifies authoritative data sources
- Shows which data is trusted and certified
- Provides validated query examples
Accuracy Impact: 50-65% (understands meaning but lacks calculation logic)
Capture Strategy:
Many enterprises have invested heavily in data catalogs but struggle with adoption and completeness. Common issues:
- Only 30-40% of columns have business descriptions
- Glossary terms don’t link to actual data assets
- Golden queries exist but aren’t tagged/findable
- Certification workflows exist but aren’t followed
Context engineering requires treating catalog population as continuous practice, not one-time project. Automated metadata extraction, crowdsourced definitions, and integration with analyst workflows all improve completeness.
Example Technologies:
- Alation (business glossary, golden queries, stewardship)
- Collibra (governance workflows, data quality integration)
- Atlan (modern catalog with collaboration features)
- Databricks Unity Catalog (lakehouse governance)
- Microsoft Purview (multi-cloud catalog)
- Open source: Amundsen, DataHub
Common Gaps:
- Incomplete coverage (only “important” tables documented)
- Stale definitions not updated as business changes
- Glossary disconnected from actual data assets
- No validation that golden queries still work
- Tribal knowledge not captured before analysts leave
Level 4: Semantic Layer (Metrics, Rules & Policies)
What It Contains:
- Metric definitions and KPI calculations (“revenue” formula)
- Business rules (fiscal calendars, inclusion/exclusion criteria)
- Dimensional hierarchies and rollup logic
- Access policies and row-level security rules
- Ontologies defining business concepts and relationships
Where It Lives Today:
- BI semantic layers: Tableau (data sources), Looker (LookML), Power BI (semantic models)
- Transformation tools: dbt (metrics layer), AtScale, Cube.dev
- Warehouse-native: Snowflake Semantic Views, Databricks Unity Catalog Semantic Models
- Legacy: Universe files, OLAP cubes
Why AI Needs This:
- Ensures consistent calculations across users and tools
- Applies company-specific business rules automatically
- Enforces fiscal calendars and time period logic
- Handles dimensional hierarchies (Region → Country → State)
- Maintains alignment with existing reports and dashboards
Accuracy Impact: 75-85% (strong foundation with consistent business logic)
Capture Strategy:
Most organizations have semantic layers — but multiple, disconnected ones. Finance has metrics defined in Excel. BI teams have definitions in Tableau. Analytics engineers have dbt models. None are unified.
Context engineering requires choosing a semantic layer strategy:
- Centralized: Single semantic layer platform (independent or warehouse-native)
- Federated: Multiple semantic layers with synchronized definitions
- Hybrid: Core metrics centralized, domain-specific extensions federated
The key is making semantic layer definitions programmatically accessible so AI systems can leverage them.
Example Technologies:
- Independent platforms: AtScale, Cube.dev, Dremio
- BI tool native: Looker (LookML), Tableau (data sources), Power BI (semantic models)
- Transformation layer: dbt (metrics), MetricFlow
- Warehouse native: Snowflake Semantic Views, Databricks Unity Catalog
Common Gaps:
- Metrics defined differently across BI tools
- Business rules encoded in SQL, not documented
- Semantic layer covers reporting needs but not ad-hoc analysis
- No API access for AI systems to query definitions
- Semantic layer limited to single data platform
Level 5: Tribal Knowledge & Memory (Intent & Reinforcement)
What It Contains:
- User intent and persona-specific interpretations
- Query reuse patterns and successful answer templates
- User feedback on answer quality (corrections, validations)
- Reinforcement learning from successful queries
- Historical context from past conversations
- Ambiguity resolution based on user role/department
Where It Lives Today:
- Mostly uncaptured — exists in analyst heads and email threads
- Query logs (but not interpreted or learned from)
- Support tickets showing “correct” interpretations
- BI dashboard usage analytics
- Slack/Teams conversations about data questions
Why AI Needs This:
- Personalizes responses based on user role and preferences
- Reuses validated queries for common questions
- Learns from corrections and feedback
- Adapts to ambiguous questions based on context
- Maintains conversation state across multiple turns
- Captures “why” decisions were made, not just “what”
Accuracy Impact: 94-99% (production-grade AI with continuous improvement)
Capture Strategy:
This is the frontier of context engineering. Few organizations systematically capture tribal knowledge. It requires:
Feedback loops: Mechanisms for users to validate/correct AI answers
Query mining: Analyzing successful query patterns to create templates
Persona modeling: Understanding how different roles interpret terms
Memory systems: Maintaining conversation and user preference history
Reinforcement learning: Improving over time from interactions
Without Level 5, accuracy plateaus at 75-85%. With Level 5, systems continuously improve toward 94-99%.
Example Technologies:
- Emerging: LLM fine-tuning on query-answer pairs
- Custom: Internal memory and preference systems
- Query analysis: Analyzing logs for patterns
- Feedback systems: Thumbs up/down, correction workflows
- Context retention: Conversation state management in agent platforms
Common Gaps:
- No systematic capture of tribal knowledge
- Query logs exist but not mined for patterns
- User feedback not used for model improvement
- Persona-specific preferences not tracked
- Intent resolution happens manually, not systematically
Where Context Lives: The Current State
Here’s the reality for most enterprises:
| Context Level | Primary Location | Typical Completeness | Accessibility for AI |
|---|---|---|---|
| Level 1: Technical Metadata | Database schemas | 90-100% | High (APIs exist) |
| Level 2: Relationships | ERDs, documentation | 40-60% | Low (PDFs, Visio) |
| Level 3: Business Definitions | Data catalogs | 30-50% | Medium (APIs exist but coverage incomplete) |
| Level 4: Semantic Layer | BI tools | 50-70% | Low (locked in tools) |
| Level 5: Tribal Knowledge | Analyst heads | 5-10% | Very Low (uncaptured) |
The Fragmentation Reality:
An enterprise might have:
- 5 data warehouses/platforms (5 copies of Level 1)
- 3 ERD tools + undocumented relationships (fragmented Level 2)
- 2 data catalogs with partial coverage (incomplete Level 3)
- 4 BI tools with inconsistent metrics (conflicting Level 4)
- Zero systematic capture of Level 5
AI systems needing unified context face an integration nightmare.
The Accuracy Progression: Why All Five Levels Matter
Research consistently shows accuracy improvements as organizations add context levels:
Level 1 Only: 10-20% Accuracy
What AI Can Do:
- Generate syntactically valid SQL
- Reference tables and columns that exist
- Avoid obvious errors like wrong data types
What AI Cannot Do:
- Determine which tables to join
- Apply business logic or rules
- Understand business term meanings
- Calculate metrics consistently
Example Failure:
Question: “What’s our Q4 revenue?”
AI with Level 1: Queries transactions.revenue column directly
Reality: Should join transactions → customers → products, filter by fiscal Q4, exclude test accounts, subtract refunds — none of which is in Level 1
Levels 1-2: 30-40% Accuracy
What AI Can Do:
- Join related tables correctly
- Avoid many-to-many explosion errors
- Follow documented relationship paths
What AI Cannot Do:
- Know “revenue” means net after refunds
- Apply fiscal calendar vs. calendar year
- Understand business term semantics
Example Failure:
Question: “What’s our Q4 revenue?”
AI with Levels 1-2: Joins tables correctly, queries all transactions in Q4
Reality: Used calendar Q4 instead of fiscal Q4, included test transactions, calculated gross not net
Levels 1-3: 50-65% Accuracy
What AI Can Do:
- Understand business term meanings
- Identify certified/authoritative data
- Map business language to technical names
What AI Cannot Do:
- Apply complex metric calculations
- Enforce business rules consistently
- Handle fiscal calendar logic
Example Failure:
Question: “What’s our Q4 revenue?”
AI with Levels 1-3: Understands “revenue” definition, queries correct tables
Reality: Didn’t apply revenue recognition rules, summed wrong, ignored fiscal calendar
Levels 1-4: 75-85% Accuracy
What AI Can Do:
- Calculate metrics consistently across queries
- Apply business rules and fiscal calendars
- Enforce row-level security and policies
- Match BI dashboard calculations
What AI Cannot Do:
- Adapt to persona-specific interpretations
- Learn from past query successes/failures
- Maintain conversation context
- Improve over time from feedback
Example Failure:
Question: “What’s our Q4 revenue?”
AI with Levels 1-4: Calculates correctly using semantic layer
Reality: CFO wanted recognized revenue (not bookings), Finance team wanted a different breakdown than Sales team — persona-specific nuances missing
Levels 1-5: 94-99% Accuracy
What AI Can Do:
- Everything from Levels 1-4, plus:
- Adapt answers based on user role/preferences
- Reuse successful query patterns
- Learn from corrections and feedback
- Maintain conversation state
- Continuously improve from interactions
Production Reality:
Question: “What’s our Q4 revenue?”
AI with Levels 1-5:
- Knows fiscal Q4 (Level 4)
- Knows user is CFO, so wants recognized revenue (Level 5)
- Remembers last time CFO asked about revenue, they wanted regional breakdown (Level 5)
- Calculates correctly, presents in CFO’s preferred format (Level 5)
The Scale Problem: Why Manual Context Building Fails
Many organizations approach context building domain by domain:
Year 1: Build complete context for Finance domain
Year 2: Build complete context for Sales domain
Year 3: Build complete context for Operations domain
Years 4-10: Continue across dozens of domains
This approach fails for three reasons:
1. Linear Time, Exponential Domains
Enterprises have dozens of business domains. At one domain per year, comprehensive context takes a decade. By then, early domains are stale and need rebuilding.
The Math:
- Average enterprise: 20 business domains
- Manual context building: 6-12 months per domain
- Total timeline: 10-20 years
- Context staleness: Definitions change, metrics evolve, teams reorganize
Manual doesn’t scale.
2. Context Isn’t Domain-Isolated
Finance “revenue” connects to Sales “bookings” connects to Operations “fulfillment.” Building context for one domain requires understanding adjacent domains.
Cross-domain dependencies create:
- Circular dependencies (can’t finish A without B, can’t finish B without A)
- Duplication (same metric defined differently in Finance and Sales)
- Gaps (metrics spanning domains fall through cracks)
3. Continuous Maintenance Overhead
Context isn’t build-once-use-forever. It requires continuous maintenance:
- Schemas change, relationships update
- Business definitions evolve, metrics change
- People leave, taking tribal knowledge
- New data sources join the ecosystem
Organizations building domain-by-domain spend all maintenance effort on existing domains, never reaching new ones.
The Scalable Approach: Context Engineering as Practice
Instead of manual domain-by-domain building, successful organizations adopt context engineering as continuous practice:
Principle 1: Aggregate, Don’t Rebuild
Most context already exists — it’s just fragmented. Focus on aggregating existing context from current tools:
Level 1: Already in databases (aggregate via APIs)
Level 2: Partially in ERDs and data models (import and supplement)
Level 3: Partially in catalogs (increase coverage, synchronize)
Level 4: Partially in BI tools (unify definitions across tools)
Level 5: Partially in query logs and support tickets (mine and formalize)
Time Comparison:
- Manual rebuild: 6-12 months per domain
- Aggregate existing: 2-4 weeks per domain for initial capture
- Ongoing maintenance: Automated synchronization
Principle 2: Automate Synchronization
Context changes continuously. Manual updates don’t scale. Automate:
Level 1-2: Automated metadata extraction on schema changes
Level 3: Automated propagation of catalog updates to downstream systems
Level 4: Semantic layer updates trigger re-synchronization
Level 5: Continuous learning from query logs and feedback
Technology Patterns:
- Event-driven architectures triggering context updates
- APIs for bidirectional synchronization
- Change data capture on metadata systems
- Scheduled reconciliation jobs catching drift
Principle 3: Prioritize by Value
Not all context is equally valuable. Prioritize:
By domain: Finance and Sales typically generate more queries than HR or Legal
By metric: Top 20 metrics account for 80% of queries
By user: Executive queries have different accuracy requirements than exploratory analysis
Start with high-value/high-frequency context, expand systematically.
Principle 4: Enable Crowdsourcing
Context engineering can’t be centralized bottleneck. Enable:
Data producers to document their datasets (Level 1-2)
Domain experts to define business terms (Level 3)
Analysts to formalize metrics (Level 4)
Users to provide feedback (Level 5)
Governance still approves, but capture is distributed.
Implementation Roadmap: From Fragmented to Unified
Phase 1: Assessment (Weeks 1-2)
Map current state:
- Where each level lives today
- Completeness within each level
- Integration gaps between levels
- AI accuracy baseline with current context
Prioritize domains:
- High-query-volume domains first
- High-business-value metrics first
- Domains with existing strong context
Deliverable: Context architecture assessment report with baseline accuracy metrics
Phase 2: Foundation (Weeks 3-8)
Aggregate Levels 1-3:
- Import technical metadata from all data sources (Level 1)
- Document/import relationship models (Level 2)
- Consolidate catalog definitions across tools (Level 3)
Quick wins:
- Automated schema synchronization
- Relationship discovery from query logs
- Catalog API integrations
Milestone: 50-65% accuracy on priority domains
Phase 3: Unification (Weeks 9-16)
Integrate Level 4:
- Audit semantic layers across BI tools for inconsistencies
- Choose centralized or federated semantic layer strategy
- Make semantic layer programmatically accessible
- Synchronize metric definitions across tools
Establish synchronization:
- Automated propagation of definition changes
- Version control for context changes
- Testing framework for context updates
Milestone: 75-85% accuracy on priority domains
Phase 4: Continuous Learning (Weeks 17-24)
Build Level 5:
- Implement feedback mechanisms for AI answers
- Mine query logs for successful patterns
- Develop persona models for different user roles
- Build memory and preference systems
Enable improvement:
- Reinforcement learning from corrections
- A/B testing of context enhancements
- Metrics tracking accuracy over time
Milestone: 90%+ accuracy with continuous improvement trajectory toward 94-99%
Phase 5: Scale (Months 6-12)
Expand coverage:
- Add additional domains systematically
- Increase completeness within existing domains
- Extend to less-frequently-queried data
Mature practice:
- Context engineering as BAU practice
- Automated quality monitoring
- Self-service context contribution
Milestone: Enterprise-wide context architecture supporting 94-99% accuracy
Technology Architecture Patterns
Pattern 1: Centralized Context Hub
Architecture:
- Single unified context repository aggregating all five levels
- APIs exposing context to all downstream systems
- Bidirectional sync with source systems (catalogs, BI tools, databases)
Pros:
- Single source of truth for context
- Simplified governance and versioning
- Consistent context across all AI systems
Cons:
- Requires significant upfront integration effort
- Single point of failure risk
- May duplicate context already in specialized tools
Best For: Organizations with strong central data teams and willingness to invest in unified platform
Pattern 2: Federated Context with Synchronization
Architecture:
- Context remains in specialized tools (catalogs, BI tools, etc.)
- Context synchronization layer propagates changes across systems
- AI systems query multiple context sources dynamically
Pros:
- Leverages existing tool investments
- Specialists continue using familiar tools
- Lower initial integration effort
Cons:
- Complex synchronization logic required
- Drift and inconsistency risks
- Performance overhead of multi-system queries
Best For: Organizations with mature tooling and reluctance to centralize
Pattern 3: Hybrid
Architecture:
- Centralized for Levels 1-2 (technical foundation)
- Federated for Levels 3-4 (business and semantic)
- Centralized for Level 5 (memory and learning)
- Synchronization ensuring consistency
Pros:
- Balances centralization and federation
- Foundation (1-2) and learning (5) benefit from unification
- Business context (3-4) stays close to domain experts
Cons:
- Most architecturally complex
- Requires sophisticated synchronization
Best For: Most enterprises — pragmatic balance of centralization and federation
Promethium’s Approach: Accelerating Context Engineering
While this guide is intentionally vendor-neutral on architecture patterns, it’s worth noting how context aggregation platforms accelerate the timeline and reduce the cost of context engineering.
Traditional Approach:
- 6-12 months to manually build context for first domain
- Custom integration code for each source system
- Manual synchronization and maintenance
- Years to achieve enterprise coverage
Context Aggregation Platform Approach:
- 2-4 weeks to aggregate existing context for first domain
- Pre-built connectors to common systems (catalogs, BI tools, databases)
- Automated synchronization and drift detection
- Months to achieve enterprise coverage
Key Acceleration Factors:
Pre-built Integrations: Instead of custom-coding connections to Alation, Tableau, dbt, Snowflake, etc., use pre-built connectors that extract and synchronize context automatically.
Unified Model: Instead of mapping each system’s metadata model to your own, adopt a unified context model that works across all sources.
Automated Synchronization: Instead of building change detection and propagation logic, leverage platforms designed for real-time context synchronization.
Level 5 Capabilities: Instead of building custom memory and reinforcement learning systems, use platforms purpose-built for continuous improvement from feedback.
The time and cost curve changes dramatically:
- Traditional: $2M+ in engineering effort over 12-24 months
- Platform-accelerated: $500k in licensing + configuration over 3-6 months
This isn’t a product pitch — it’s recognition that context engineering as a discipline benefits from purpose-built tooling, just as data engineering benefited from Airflow, dbt, and Fivetran.
Measuring Context Architecture Success
Leading Indicators (Weeks 1-8)
Coverage Metrics:
- Percentage of tables with Level 1-2 context
- Percentage of columns with Level 3 business definitions
- Percentage of metrics with Level 4 formalized calculations
- Number of Level 5 feedback loops established
Integration Metrics:
- Number of context sources integrated
- Synchronization latency (time from source change to unified context update)
- API response times for context queries
Operational Metrics (Weeks 8-16)
Quality Metrics:
- Context completeness score by domain
- Context freshness (time since last update)
- Conflicting definition count (same term, different meanings)
- Orphaned context (definitions not linked to data assets)
Usage Metrics:
- AI queries leveraging unified context
- Reduction in manual analyst interventions
- Query success rate improvements
Business Outcomes (Months 4-12)
Accuracy Metrics:
- AI query accuracy by context level (target: 94%+ with all five levels)
- Query failure rate reduction
- User-reported incorrect answer rate
Efficiency Metrics:
- Time to answer business questions (target: <5 minutes vs. hours/days)
- Analyst time saved from routine queries
- Reduction in “why don’t these numbers match?” support tickets
Strategic Metrics:
- AI adoption rate across business users
- Number of domains covered by unified context
- Time to add new data sources with complete context
Common Mistakes and How to Avoid Them
Mistake 1: Treating Context as One-Time Project
Problem: Build context once, declare success, move on
Reality: Schemas change, metrics evolve, people leave with tribal knowledge
Solution: Context engineering as continuous practice with dedicated ownership
Mistake 2: Perfect Before Progress
Problem: Wait to document all context before enabling AI
Reality: 80% accuracy with partial context beats 0% waiting for perfection
Solution: Start with high-value domains, expand systematically, improve iteratively
Mistake 3: Central Team Bottleneck
Problem: Single data governance team responsible for all context capture
Reality: Team of 5 can’t document context for 10,000 tables and 500 metrics
Solution: Distributed capture with centralized governance — producers document, governance approves
Mistake 4: Ignoring Levels 2 and 5
Problem: Focus exclusively on catalog (Level 3) and semantic layer (Level 4)
Reality: Without relationships (2) and learning (5), accuracy plateaus at 75-85%
Solution: Systematic approach to all five levels, not just the “visible” ones
Mistake 5: Building in Silos
Problem: Different teams build context for their domains independently
Reality: Cross-domain queries fail, definitions conflict, integration nightmare
Solution: Unified context model with federated capture — consistent structure, distributed effort
The Future of Context Engineering
Context engineering as a discipline is still emerging. Expect maturation in:
Automated Context Discovery: AI systems mining query logs, documentation, and conversations to automatically suggest context
Active Learning: Systems that ask users for context when encountering ambiguity, learning from responses
Context Markets: Organizations sharing sanitized context patterns (e.g., “how Fortune 500 companies define churn”)
Standardization: Emerging standards for context exchange (like dbt’s semantic layer specification)
Context Observability: Tooling that monitors context drift, staleness, and quality like data observability tools today
Organizations investing in context engineering now build competitive advantages as AI adoption scales.
Conclusion: Context Is as Important as Data
For the past decade, enterprises focused on aggregating data. Modern data stacks move terabytes efficiently. Real-time pipelines keep everything current. Cloud platforms scale elastically.
But data without context is just bytes. Context transforms data into insights.
The same discipline applied to data engineering must now apply to context engineering:
- Systematic capture across all five levels
- Automated synchronization keeping context current
- Unified architecture making context accessible
- Continuous improvement adapting as business evolves
Organizations that master context engineering achieve 94-99% AI accuracy. Those that leave context fragmented struggle at 10-20%.
The choice is clear: invest in context architecture now, or watch AI initiatives stall at pilot stage.
Context engineering isn’t a nice-to-have. It’s the foundation for production AI. To see how Promethium allows you to talk to all your data by dynamically aggregating your context, schedule your demo today.


