

With AI, ad hoc analytics of structured enterprise data has become a topic of research and excitement. Ad hoc has always been the goal of true self-service. The idea of “talk to my data” agents is to enable business analysts and operational leaders to engage conversationally in real-time with their data and apps to build immediate insights to drive business decisions.There has been an explosion of agents across each part of the stack (BI, data platforms, catalogs, data engineering, etc.) and after a year of agentic POCs, enterprises have mostly concluded that these platform-specific agents fall short of meeting the accuracy threshold required for production use. Accuracy is not a static threshold. It is useful to think of an accuracy vs. cost curve – typically an S curve as shown below. Today it takes a very long time and effort (cost) of context engineering on the enterprise data to get to the required accuracy threshold. There is no scalable solution today that works across domains, data platforms and apps. By the way, this is not just a text-to-sql problem, which the LLMs are getting more capable in translation. This is a broader (and harder) problem of answering an ad hoc business question with an accurate and contextual business answer and insight.

Let’s understand the architectural reasons behind this challenge. See the diagram on AI Disconnect below.
First, high value ad hoc questions typically require access to data that spans multiple platforms. Just as a simple example, some of your customer data may be in Salesforce, while the product data may be in Snowflake (or Databricks or a cloud data platform). The customer analytics problem may require querying and joining data on both these platforms. In a large enterprise, there are dozens of core platforms and applications that support high value data. Insights may require spanning and dynamically joining information across these platforms. Even when most of the data is supposed to be consolidated in a single modern platform, the reality may be that high value data still resides on an older legacy platform, so accessing data wherever it lives is an important requirement. Also, some of these platforms may be in the cloud, others could be in private clouds or data centers. Hybrid data is a reality of the large enterprise. Today, there is no easy way to access data in real-time across multiple data stores without moving the data or constructing a pipeline ahead of time.

Secondly, business questions use business terms and mapping these terms and intent to the right enterprise data is a non-trivial context engineering task. When a CRO asks an ad hoc question on revenue tied to specific territories on a specific product category, both technical metadata and business context have to be combined, in addition to persona-specific intent and preferences. A financial analyst asking similar questions could lead to a different logic with different data sets. And this context is fragmented within the enterprise today, with no consistency of practice. For example, business rules or golden queries may be partially in catalogs, and the definitions and measures tied to past dashboards may be in the semantic layer within BI dashboards. In other cases, context is in documents or in analyst heads! Successful and experienced analysts will navigate this ambiguity and are able to build data products based on their experience across a messy enterprise data environment. But this is not an easily repeatable or scalable process for other team members. And the wider the data across platforms, the messier the context gets.
How much context is needed? What is the right context? These are all subjective questions that depend on each enterprise, and sometimes, each domain (or department) within that enterprise. That’s what makes this particularly hard to repeat and scale. The framework below shows that there are different types of context that need to be layered for contextual engineering of reliable insights, depending on the persona and problem/intent.
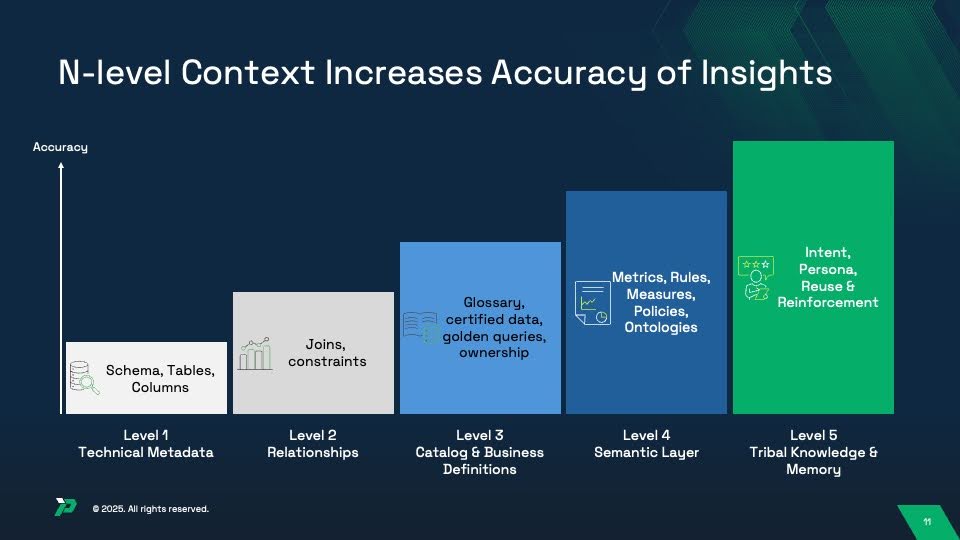
Finally, to enable true self-service on ad hoc questions, the business users and analysts within each domain need insights within their specific environments, agents, channels or tools. The goal should be to meet them where they are. Maybe the end user is in CoPilot or Enterprise ChatGPT or Teams/Slack or within the enterprise-specific bot or BI agent. Accuracy of insights is a subjective experience dictated by the end user intent and capabilities. Power users that have complex hypotheses require an iterative hands-on experience while casual business users may only ask simple questions with single shot responses (associated with a high level of impatience!). The specific agent memory has to inherit and reflect the persona and the domain. Today most agents are statically tied to specific platforms or context stores, and not dynamically linked across them. Agent engineering for true self-service requires “any to any” linkage, meaning any channel for any user should be linked to any data platform and context source (subject to access control) and the specific linkage should be dynamically provisioned based on the question being asked. There is too much friction with platform-specific agents to enable effective self-service today.
Accelerating and Scaling Accuracy of Insights Across the Enterprise
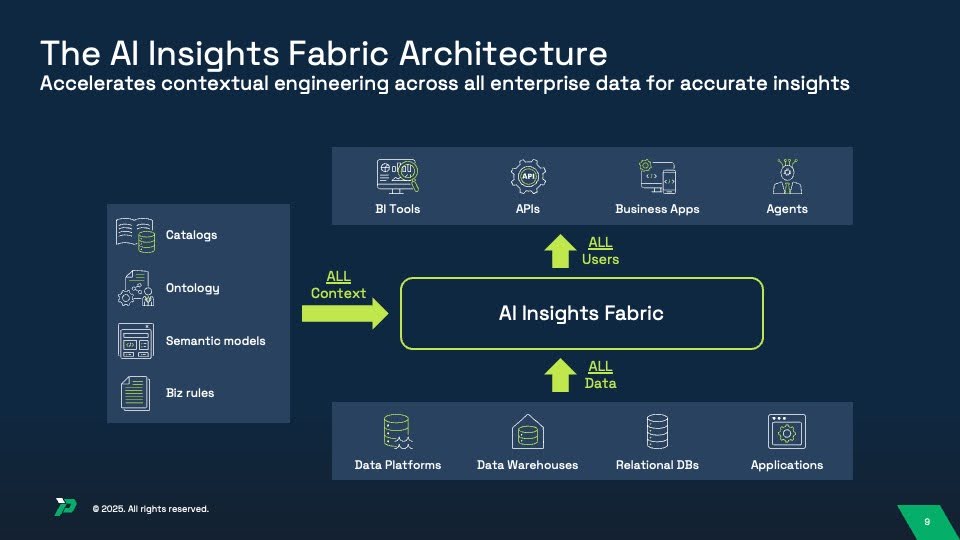
Promethium’s AI Insights Fabric (AIF) is an open agentic platform that addresses the architectural problem of accelerating the accuracy of insights while scaling the cost of context engineering across business domains. The platform brings together real-time distributed data access and distributed context engineering with self-service agent engineering to cost-effectively enable business users with accurate insights. It is an open and flexible platform in the sense that it makes no assumptions of which agent or channel or tool will request/consume the insights, nor where the data is actually stored, or where the context resides. The AIF platform can operate in a headless manner (via MCP or similar protocols and API’s) so that any agent or AI model can connect to it. It also provides an agent called Mantra that provides an iterative environment for business users that want to build insights themselves.
In my next blog, I will dive into the agentic architecture and capabilities of AIF and take you through a Mantra demo.


