
Data is everywhere! So when business leaders need data to support decisions data needs to be pulled from many different source systems.
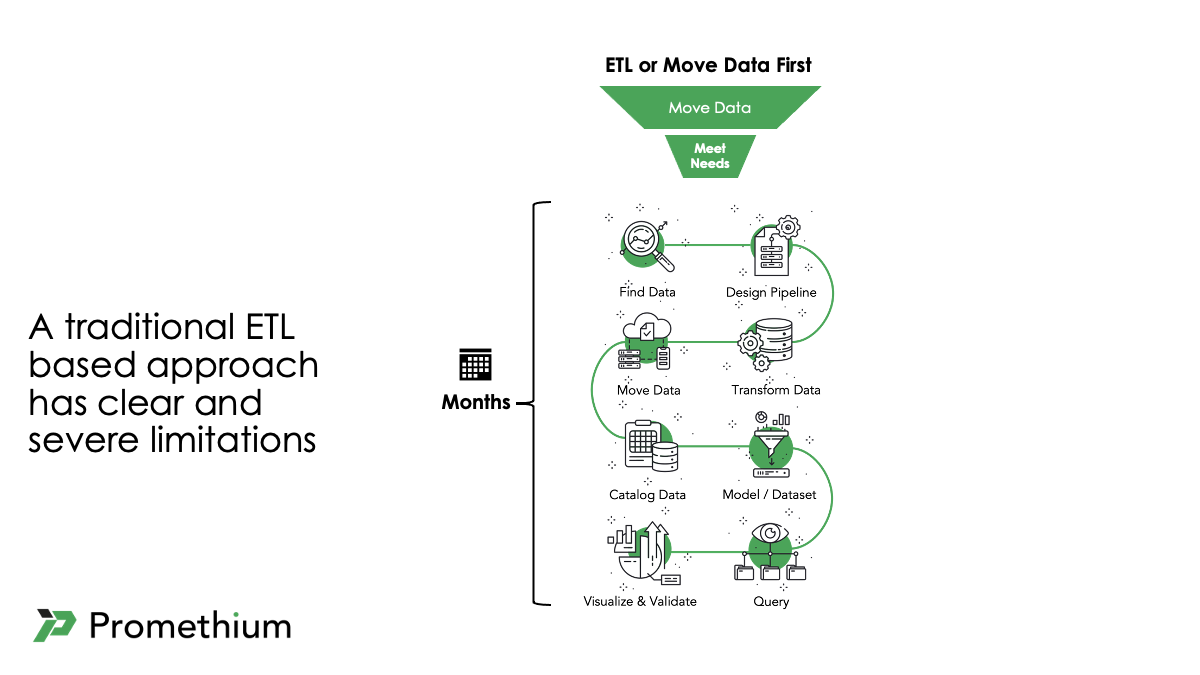
The traditional approach is to use complex and rigid ETL to consolidate data to a central repository, like a data warehouse. The limitations of this approach are clear and include:
It’s not possible to move all enterprise data to a central repository
Finding, validating and consolidating data for new needs can take months
Data needs to be moved before business needs can be met
Consumes thousands of hours each year – that time that could be better spent
ETL is rigid, and once implemented making changes is very difficult
Data volume and demand is growing, but the windows for ETL jobs to move data are not
Data Fabric Data Pipelines
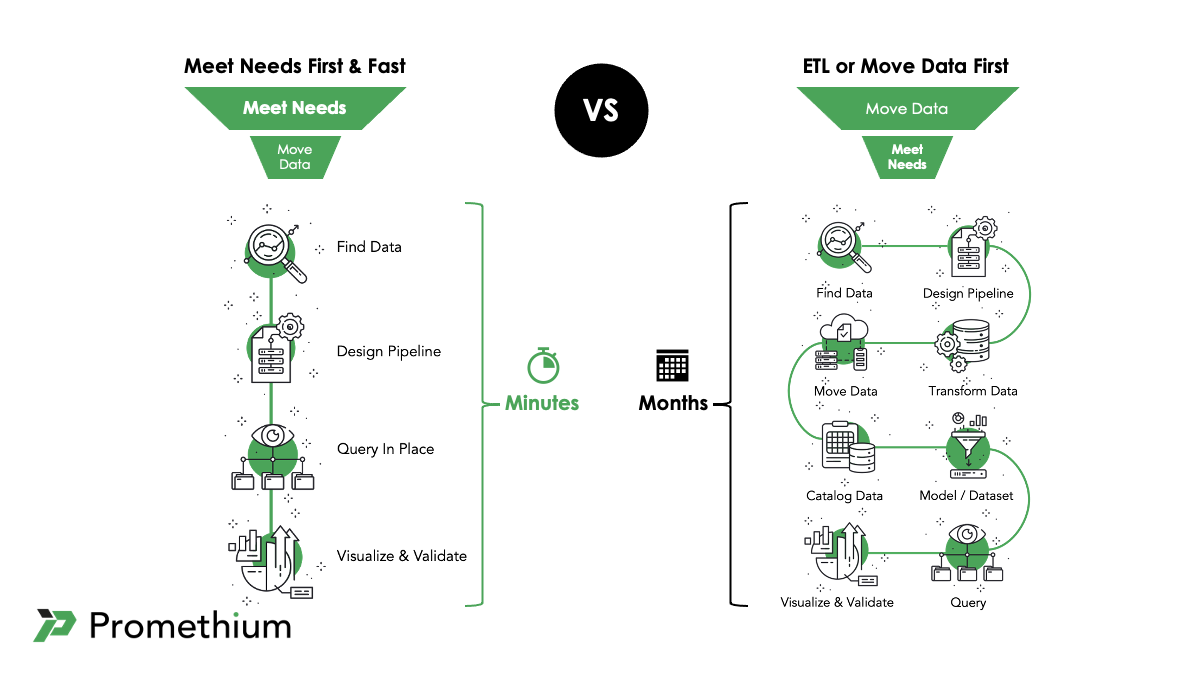
Data Fabric promises to be the ideal solution to address the limitations of the traditional ETL approach. In sharp contrast to the traditional approach, Data Fabric is flexible and agile by design. Data Fabric’s special data pipelines are a key reason.
What makes Data Fabric data pipelines so special is that they don’t rely on persisting data first and they make it possible to perform analysis on data from many sources on-the-fly. This is how Data Fabric data pipelines compare:
Data Fabric Pipelines | Traditional Approach |
Access data where it lives | Access data from central repository after it is moved |
Ingest, transform and integrate data on the fly without persisting into data lakes, data warehouses, NoSQL or object stores | Persisting data is required |
See results in real time at each step | See results after data is transformed and moved |
Make changes to pipelines in real time | Changes are difficult and can result in building new vs changing existing |
Doesn’t require data duplication | Results in many duplicate copies of data being stored and managed |
The Applications
When applied to specific situations Data Fabric data pipelines can significantly boost performance for data analytics.
Self Service Data: Complexity and technical skills have stood in the way of self service data. Data Fabric data pipelines fix the problems by solving data integration challenges and reducing the need for technical skills.
Self Service Analytics: Pre-built dashboards with filters that query out of date data warehouses are a poor excuse for self service analytics. Replace the rigid data warehouse with Data Fabric data pipelines that enable on-demand federated queries directly against the latest data.
Rapid Idea Testing: Quickly testing data analytics ideas just isn’t possible when data lives in different systems and needs to be extracted, transformed and persisted somewhere first. Because Data Fabric data pipelines do everything on the fly without persisting data new ideas can be tested quickly.
New Data Sources: The business needs a new data source added to data already in the data warehouse, but there just isn’t time. Data Fabric data pipelines can join the data from the new datasource with the new data source on-the-fly.
Cloud Data Warehouse or Lake: While cloud solutions offer many benefits, costs can grow quickly. Data Fabric data pipelines minimize the amount of data that actually needs to be moved to cloud solutions. Keep cloud costs under control and
Benefits
With the help of Data Fabric data pipelines it’s possible to focus on meeting business needs first before ever moving data. That means more satisfied business stakeholders who can made decisions backed by data.
Benefits include:
Faster: Not waiting for complex and rigid ETL jobs to be built and not waiting for data to be moved makes data analytics faster.
More Productive: The time to complete data jobs is decreased making it possible for resources to do more.
Less Cost: Less data duplication and management helps to avoid costs.
Business Outcomes: Business outcomes are what really matter, and making more data available faster can drive more and better business outcomes.
Data Fabric data pipelines have the potential to help data and analytics leaders reimagine data analytics.
Learn More
Watch the data pipeline design expert session with Deloitte
Try it yourself. All you need is 10 minutes. Try now


