The explosion of “talk to your data” agents has created a new bottleneck that most enterprises underestimate: context engineering.
By now, AI can translate natural language to SQL impressively well. The models are getting better at generating syntactically correct queries. But accuracy in production remains stubbornly low. Multiple benchmarks — including BIRD and Spider — show that in real-life enterprise environments, accuracy breaks down quickly and dramatically.
The problem isn’t the SQL generation itself. It’s understanding what business terms actually mean in your organization. When someone asks about “revenue,” does that mean gross revenue, net revenue, recognized revenue, or booked revenue? Which fiscal period? Which business unit’s definition? What about returns and adjustments?
Generating syntactically correct SQL is one piece. Mapping business meaning to data — that’s the critical piece most organizations underestimate.
Think of context engineering as an accuracy versus cost curve. Initially, progress is slow — you’re manually documenting definitions, building glossaries, curating business rules. Then, if you invest enough, accuracy starts to improve rapidly once a certain threshold is met. Eventually, it plateaus.
The challenge: For most enterprises, getting to that inflection point takes 6-12 months of dedicated effort per domain. And most enterprises have 8-12 major domains.
Do the math. That’s years of sequential work. And by the time you finish domain twelve, domain one’s context is outdated because the business has evolved over time.
This isn’t a resourcing problem you can hire your way out of. It’s an architectural problem that requires fundamentally rethinking how context gets created, maintained, and delivered to AI systems.
The Architectural Reality Behind Enterprise Data
When you dig into why AI accuracy remains low in production, three architectural problems emerge:
Distributed Data: High-value business questions require data from multiple platforms. Customer data lives in Salesforce, product data in Snowflake, operational metrics in legacy systems. AI needs to query and join across these platforms in real-time — but most architectures can’t do this without pre-built pipelines.
Fragmented Context: Business definitions live everywhere and nowhere. Some rules are in data catalogs. Metrics are embedded in BI semantic layers. Calculation logic exists in analyst heads. There’s no consistent practice for capturing or applying business context. The wider the data spans across platforms, the messier the context gets.
Scalability Gap: Even if you solve these problems for one domain, you need to repeat the entire process for the next. Each domain takes 6-12 months of context curation. The organizational scaling timeline becomes insurmountable.
This is why most enterprises are stuck on the slow part of the accuracy curve, investing heavily in context engineering with limited results.
How Most Organizations Try to Solve It (And Why It Breaks)
When enterprises realize their AI needs better context, they typically try one of three approaches. Each shows promise in controlled scenarios. None scales across enterprise complexity.
Approach 1: Prompt Engineering with Schema Context
Teams embed context directly into prompts — CREATE TABLE statements, sample values, business rules, and query patterns. They use structured tags to separate instructions from schema information, add sample column values for low-cardinality fields, and prune irrelevant columns to manage token limits.
This works for focused use cases with stable schemas under 50 tables but breaks when business logic changes frequently or context requirements vary by user and domain.
And while academic benchmarks show some promise in settings to the tune of 80-90% accuracy, in real life scenarios accuracy quickly drops below 20%.
Approach 2: RAG with Vector Search
Store schema documentation, business rules, and historical queries in vector databases. When AI needs context, retrieve relevant documents based on semantic similarity before generating SQL. Production implementations show search hit rates can hit up to 90% for relevant tables with well-constructed documentation.
Vector search retrieves semantically similar content, not necessarily correct content — it can’t distinguish between different business contexts when terminology overlaps. The BEAVER benchmark found leading models achieved close to 0% end-to-end execution accuracy on real enterprise schemas, with 59% of failures from incorrect column mapping.
One organization we’ve spoken with has approximately 40 different definitions of “cost per ton” — metric ton or imperial ton, which currency, what cost components, which business unit’s accounting rules. RAG systems retrieve documents containing “cost per ton” but can’t distinguish which definition applies to the specific business question or department asking it. The result: confidently presented results that are contextually incorrect.
Approach 3: Manual Semantic Layer Construction
Build semantic layers, data glossaries, and business rule repositories from scratch. Document every definition, curate every metric, map every relationship between systems, and encode business logic in structured formats — YAML definitions, REST APIs, or proprietary specifications. Research shows that with properly governed definitions and semantic context accuracy can improve significantly.
But implementation cost may be prohibitive at scale. One financial services company invested several million dollars working with a systems integrator to build a comprehensive semantic layer for a single domain — the project succeeded technically but never made it to production because even within that single domain, the cost and complexity of maintaining it was too high; not too mention that none of these efforts scaled efficiently to the next domain.
Why Manual Context Engineering Can’t Scale
These approaches share a fundamental flaw: they treat context engineering as a one-time documentation project rather than a dynamic, evolving capability. Three structural problems make scaling impossible.
The Hierarchy Problem
Business terminology operates at multiple levels. Some definitions are company-wide. Many are domain-specific. The same term often has different meanings in different contexts.
Take “revenue” — a seemingly straightforward metric. But depending on the domain you are in, definitions will be vastly different. And so a finance leader asking for revenue might be looking for a GAAP definition, while a sales leader asking the same question might be expecting to see ARR.
Manual context engineering forces you to choose: document everything at a granular level (creating overwhelming complexity) or stick to high-level definitions (losing the specificity needed for accurate answers). Either way, the system can’t dynamically apply the right definition based on who’s asking and what they’re trying to understand.
No Learning Between Domains
With prompt engineering or RAG, each new domain requires rebuilding everything from scratch. The finance team’s context doesn’t inform the supply chain team’s implementation. The sales operations semantic layer can’t leverage work done for marketing analytics.
You end up with isolated implementations per domain, each requiring 6-12 months of dedicated effort. There’s no mechanism for the system to learn from one domain and apply that knowledge to the next. Definitions, business rules, and usage patterns stay locked within their original scope.
Business Is Constantly Changing
Organizations reorganize. Acquisitions bring new definitions. Regulatory requirements shift. Products get discontinued and launched. Market conditions change how metrics are calculated.
Static context — whether in prompts, RAG documents, or manually maintained semantic layers — becomes outdated the moment business reality changes. Keeping context current requires continuous manual updates across all the places it’s embedded. Most organizations can’t keep up, so accuracy degrades over time even for domains they’ve already “finished.”
When context is embedded in prompts, RAG pipelines, or static semantic layers, you get fragmentation. The same business concept has different representations in different places. There’s no single source of truth. Small business logic changes ripple through dozens of implementations. Governance becomes nearly impossible because you can’t track where context is being applied.
If you have 10 major domains and each takes 6-12 months, you’re looking at 5-10 years of work. By then, business reality has evolved.
What Actually Scales: Context as Infrastructure
Organizations successfully scaling AI past the accuracy inflection point treat context differently. They don’t manually curate definitions domain by domain. They build context infrastructure that aggregates knowledge automatically and makes it accessible everywhere.
This solves both problems: reducing the cost of context engineering while accelerating time to production accuracy.
The reality: context already exists in your organization. Business definitions live in BI tools. Technical metadata sits in data catalogs. Semantic models are embedded in analytics platforms. Ontologies exist in knowledge management systems. Tribal knowledge resides in how experienced analysts actually query and interpret data.
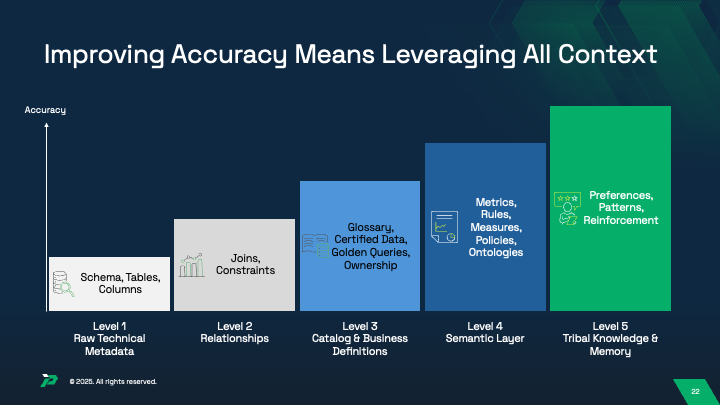
The challenge isn’t creating context from scratch. It’s aggregating what already exists, resolving conflicts where the same metric has different definitions across systems, and making that consolidated knowledge accessible to AI systems dynamically.
Three architectural shifts make this possible:
First, aggregate and unify context from existing sources. Don’t create another repository requiring manual population. Pull context automatically from data catalogs, BI tools, semantic layers, and — critically — from how people actually query and use data. The infrastructure learns from actual usage patterns, not just static documentation.
But aggregation reveals conflicts. When your BI tool defines “customer lifetime value” differently than your data warehouse semantic layer, the system needs judgment rules about which definition applies in which context. This is where human reinforcement becomes critical initially — subject matter experts validate which interpretation is correct for specific business questions, and that validation becomes part of the context layer.
Second, enable parallel domain adoption, not sequential rollouts. When context exists as infrastructure, new domains onboard by connecting their existing metadata sources. Finance doesn’t wait for marketing. Each domain contributes to and benefits from shared context simultaneously.
More importantly, context learned in one domain can inform another. If the finance team has validated how “revenue recognition” works with their data, that knowledge can help guide sales operations when they encounter similar concepts. The system learns across domains, not in isolation.
Third, let context evolve through usage and reinforcement. Don’t rely solely on upfront curation. When a subject matter expert validates an answer, that validation becomes context. When a query pattern proves reliable and gets endorsed, that pattern informs future interpretations. When business rules change, the system adapts through actual use, not only through manual documentation updates.
This is how leading financial services firms, healthcare systems, and retailers are building AI that reaches production accuracy without the multi-year context engineering burden. The difference shows up in deployment speed (weeks per domain instead of months), accuracy improvements over time (continuous learning from usage), and organizational adoption (teams don’t wait in queue for their domain).
Moving Past the Context Engineering Bottleneck
If your AI initiatives are stuck on the slow part of the accuracy curve, the problem isn’t your models. It’s not your data quality. It’s not even the technical sophistication of your data team.
It’s context engineering. Specifically, it’s trying to manually engineer context domain by domain, creating a permanent bottleneck that organizational AI can’t overcome. The cost is too high, the timeline too long, and business change too fast for manual approaches to ever catch up.
The accuracy curve doesn’t flatten because models aren’t good enough. It flattens because manual context engineering can’t scale. Infrastructure that makes context engineering automatic changes the curve entirely.
Join us for a deeper discussion on this topic: BARC’s Kevin Petrie and Promethium’s Prat Moghe explore how to break the metadata bottleneck and enable agentic AI at scale. Register for the webinar: “Break the Metadata Bottleneck to Drive Agentic AI and Contextual Insights” — January 29, 2026, 12:00 PM ET